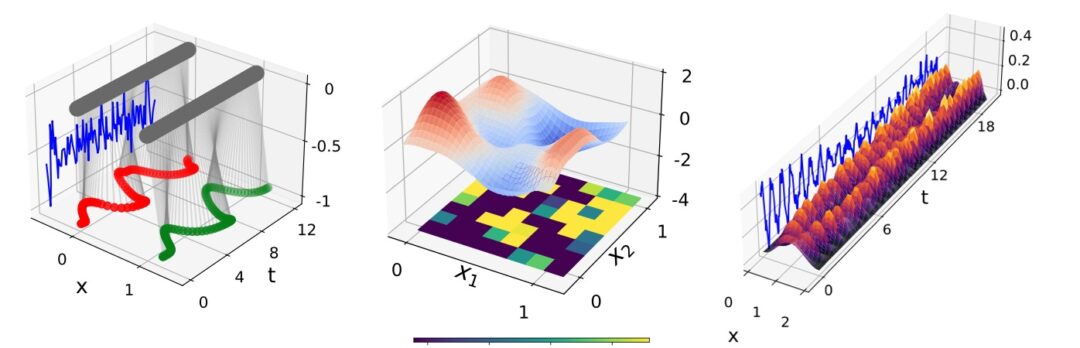
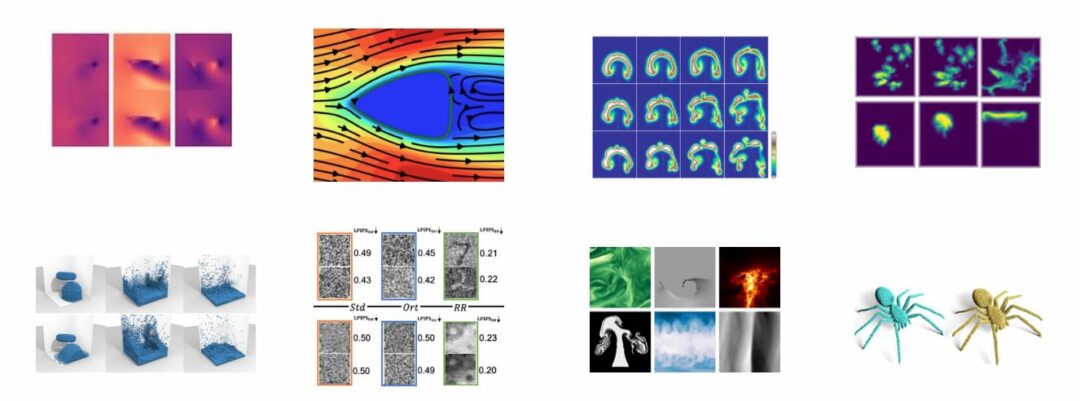
We’re happy to publish v0.2 of our “Physics-Based Deep Learning” book #PBDL. The main goal is still a thorough hands-on introduction for physics simulations with deep learning, and the new version contains a large new part on improved learning methods. The main document is available at https://www.physicsbaseddeeplearning.org/ , or as PDF at https://arxiv.org/abs/2109.05237.
Among others, we’re explaining the “scale-invariant physics” training which includes higher-order information via inverse simulators. In naturally comes with code examples, e.g., this inverse heat problem:
Also, half-inverse gradients are explained in detail now. They jointly invert physics and neural network to get optimal updates for a whole mini-batch, here’s an example implementation that runs on the spot in colab:
… and of course we fixed numerous typos throughout all chapters, cleaned up the code, and clarified explanations. Please let us know if you find any 🙂 ! This text will also serve as the basis and script for our upcoming Advanced Deep Learning for Physics (IN2298) or shortened ADL4Physics course.
We’re happy to advertise our ICLR’22 spotlight paper on half-inverse gradients (HIGs) for physics problems in deep learning. We propose a new method that bridges the gap between “classical” optimizers and machine learning methods. We’re showing its advantages and behavior for a wide range of physical problems, from a simple non-linear oscillator, over a diffusion PDE, to a quantum dipole control problem. So – no Navier-Stokes, yet – but that’s definitely an exciting outlook 😀
Abstract: Recent works in deep learning have shown that integrating differentiable physics simulators into the training process can greatly improve the quality of results. Although this combination represents a more complex optimization task than supervised neural network training, the same gradient-based optimizers are typically employed to minimize the loss function. However, the integrated physics solvers have a profound effect on the gradient flow as manipulating scales in magnitude and direction is an inherent property of many physical processes. Consequently, the gradient flow is often highly unbalanced and creates an environment in which existing gradient-based optimizers perform poorly. In this work, we analyze the characteristics of both physical and neural network optimizations to derive a new method that does not suffer from this phenomenon. Our method is based on a half-inversion of the Jacobian and combines principles of both classical network and physics optimizers to solve the combined optimization task. Compared to state-of-the-art neural network optimizers, our method converges more quickly and yields better solutions, which we demonstrate on three complex learning problems involving nonlinear oscillators, the Schroedinger equation and the Poisson problem.
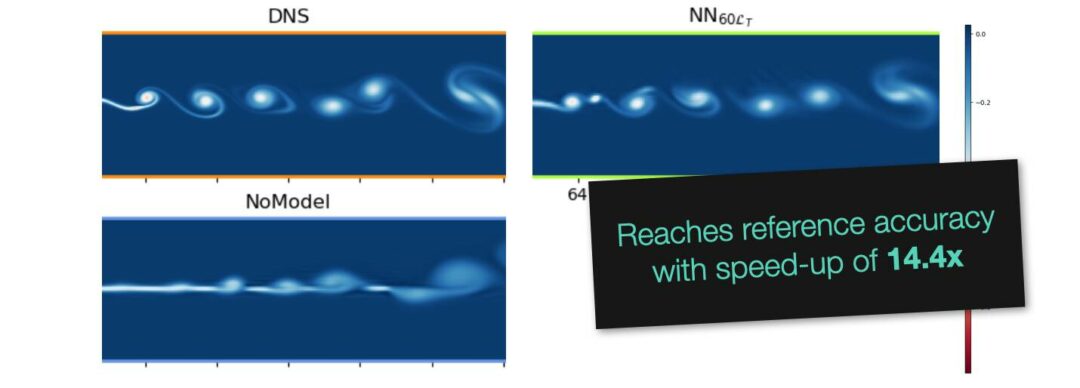
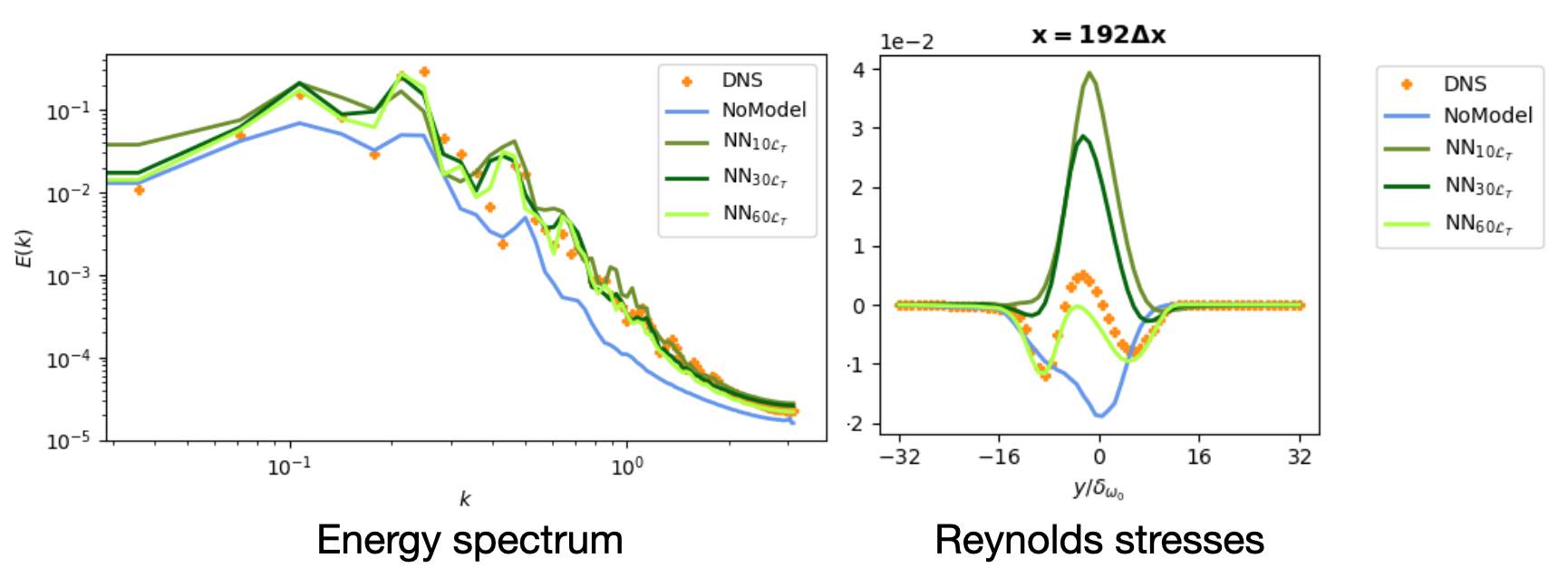
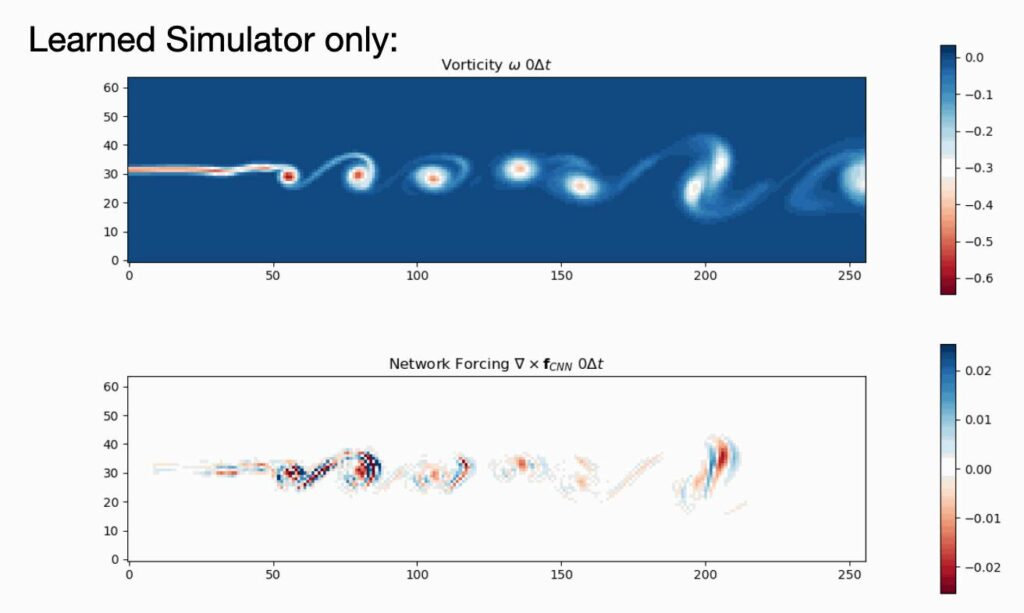
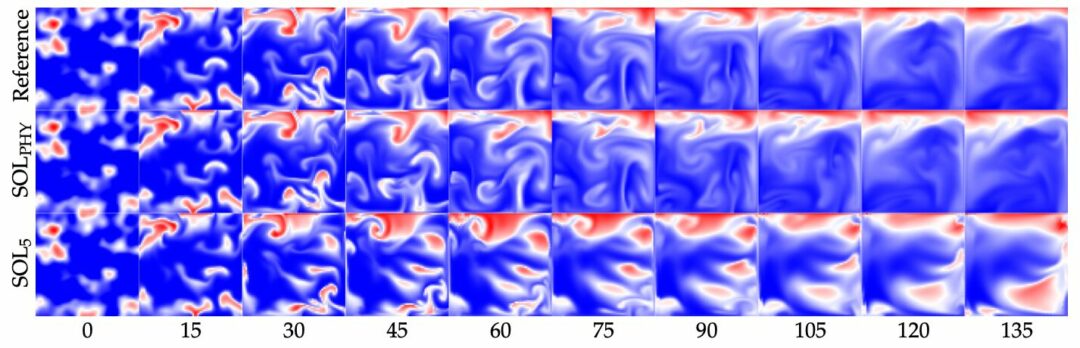
Below you can preview our newest paper on learned turbulence modeling with differentiable solvers. The learned model closely reproduces the turbulent statistics of the DNS reference, and matches it’s accuracy while being more than an order of magnitude faster. The training is performed jointly with a classic, second-order PISO solver that is made differentiable via phiflow.
This is all based on a validated second-order-in-time PISO solver, that’s integrated into neural network training with the “differentiable physics” approach.
Abstract: In this paper, we train turbulence models based on convolutional neural networks. These learned turbulence models improve under-resolved low resolution solutions to the incompressible Navier-Stokes equations at simulation time. Our method involves the development of a differentiable numerical solver that supports the propagation of optimisation gradients through multiple solver steps. We showcase the significance of this property by demonstrating the superior stability and accuracy of those models that featured a higher number of unrolled steps during training. This approach is applied to three two-dimensional turbulence flow scenarios, a homogeneous decaying turbulence case, a temporally evolving mixing layer and a spatially evolving mixing layer. Our method achieves significant improvements of long-term a-posteriori statistics when compared to no-model simulations, without requiring these statistics to be directly included in the learning targets. At inference time, our proposed method also gains substantial performance improvements over similarly accurate, purely numerical methods.
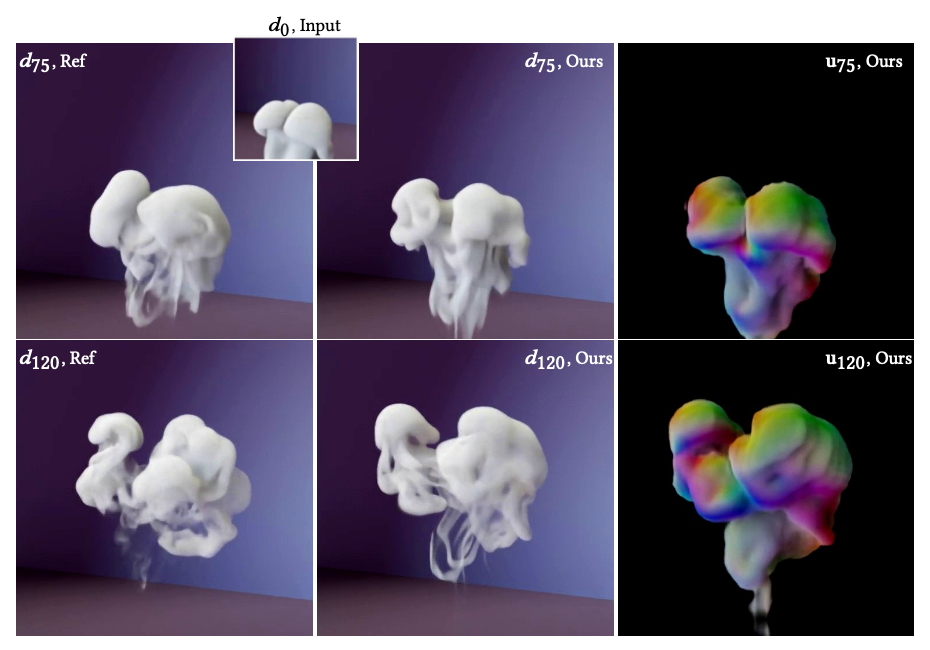
Abstract: Simulations that produce three-dimensional data are ubiquitous in science, ranging from fluid flows to plasma physics. We propose a similarity model based on entropy, which allows for the creation of physically meaningful ground truth distances for the similarity assessment of scalar and vectorial data, produced from transport and motion-based simulations. Utilizing two data acquisition methods derived from this model, we create collections of fields from numerical PDE solvers and existing simulation data repositories, and highlight the importance of an appropriate data distribution for an effective training process. Furthermore, a multiscale CNN architecture that computes a volumetric similarity metric (VolSiM) is proposed. To the best of our knowledge this is the first learning method inherently designed to address the challenges arising for the similarity assessment of high-dimensional simulation data. Additionally, the tradeoff between a large batch size and an accurate correlation computation for correlation-based loss functions is investigated, and the metric’s invariance with respect to rotation and scale operations is analyzed. Finally, the robustness and generalization of VolSiM is evaluated on a large range of test data, as well as a particularly challenging turbulence case study, that is close to potential real-world applications.
Nils (Thuerey) will give several talks on talks about differentiable simulations and deep learning for physics problems and PDEs in the next weeks. Here’s a preview, we hope to see some of our website visitors during these talks! Here’s a preview for some of them….
Abstract: In this talk I will focus on the possibilities that arise from recent advances in the area of deep learning for physical simulations. In this context, especially the Navier-Stokes equations represent an interesting and challenging advection-diffusion PDE that poses a variety of challenges for deep learning methods.
In particular, I will focus on differentiable physics solvers from the larger field of differentiable programming. Differentiable solvers are very powerful tools to integrate into deep learning processes. The existing numerical methods for efficient solvers can be leveraged within learning tasks to provide crucial information in the form of reliable gradients to update the weights of a neural networks. Interestingly, it turns out to be beneficial to combine supervised and physics-based approaches. The former poses a much simpler learning task by providing explicit reference data that is typically pre-computed. Physics-based learning on the other hand can provide gradients for a larger space of states that are only encountered at training time. Here, differentiable solvers are particularly powerful to, e.g., provide neural networks with feedback about how inferred solutions influence the long-term behavior of a physical model.
I will demonstrate this concept with several examples from learning to reduce numerical errors, over long-term planning and control, to generalization. I will conclude by discussing current limitations and by giving an outlook about promising future directions.
We have a variety of highly interesting research papers in the works. Obviously, these are work in progress, but nonetheless warrant a quick preview at this time of the year. Here are two examples which can be found on arXiv by now. The first one targets the connection of classical optimization schemes and deep learning methods for physical systems (via what we’ve dubbed “physical gradients”).
The second paper targets “incomplete” PDE solvers, i.e., solvers where only a part of the full PDE is known and available at training time, and the remainder is only specified via the training data. If you’ve worked with differentiable solvers, you can probably imagine that a neural network is able to learn the missing part of the PDE. However, it is nonetheless nice to have concrete results demonstrating this concept for several interesting and non-trivial reacting flow cases.
We’re happy to announce version 2.0 of Φ-Flow. It’s the latest version of our framework for differentiable physical simulations and deep learning: https://github.com/tum-pbs/PhiFlow
Version 2 contains numerous new features: named dimensions (no more reshaping!), support for numpy,TF,pytorch & JAX backends, with cross-platform jit compilation…
Philipp Holl, the main developer of phiflow, has also started recording his series of tutorial videos. Here’s a first one about basic math functions: https://youtu.be/4nYwL8ZZDK8
We have also just released the PDF Version of our Physics-based Deep Learning book. It can come in handy if you want to read it offline in one go: https://arxiv.org/pdf/2109.05237.pdf
Looking ahead, we’re of course also planning a printed version with extra-thick, glossy paper and a large font size so that typing up the Jupyter notebooks is extra convenient. (No, of course not 😄 – rather, please don’t print the PDF!)
In addition, there’s also an introductory video that summarizes the goals of the PBDL book, and runs through some of the highlights: https://youtu.be/SU-OILSmR1M
Its central goal is to give a thorough, hands-on introduction to deep learning for physical systems, from simple physical losses to full hybrid solvers. Best of all: the majority of the topics come with Jupyter notebooks that can be run on the spot!
The PBDL book contains a practical and comprehensive introduction of everything related to deep learning in the context of physical simulations. As much as possible, all topics come with hands-on code examples in the form of Jupyter notebooks to quickly get started. Beyond standard supervised learning from data, we’ll look at physical loss constraints, more tightly coupled learning algorithms with differentiable simulations, as well as reinforcement learning and uncertainty modeling. We live in exciting times: these methods have a huge potential to fundamentally change what we can achieve with simulations.
The key aspects that we will address in the following are:
explain how to use deep learning techniques to solve PDE problems,
how to combine them with existing knowledge of physics,
without discarding our knowledge about numerical methods.
The focus of this book lies on:
Field-based simulations (no Lagrangian methods)
Combinations with deep learning (plenty of other interesting ML techniques, but not here)
Experiments as outlook (i.e., replace synthetic data with real-world observations)
The name of this book, Physics-Based Deep Learning, denotes combinations of physical modeling and numerical simulations with methods based on artificial neural networks. The general direction of Physics-Based Deep Learning represents a very active, quickly growing and exciting field of research.
The aim is to build on all the powerful numerical techniques that we have at our disposal, and use them wherever we can. As such, a central goal of this book is to reconcile the data-centered viewpoint with physical simulations.
The resulting methods have a huge potential to improve what can be done with numerical methods: in scenarios where a solver targets cases from a certain well-defined problem domain repeatedly, it can for instance make a lot of sense to once invest significant resources to train a neural network that supports the repeated solves. Based on the domain-specific specialization of this network, such a hybrid could vastly outperform traditional, generic solvers.
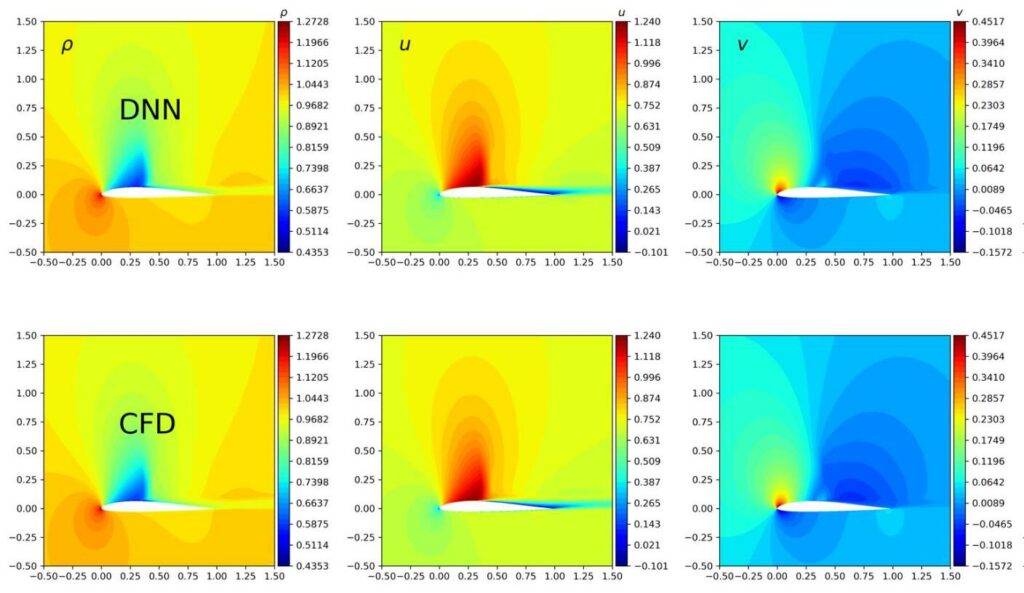
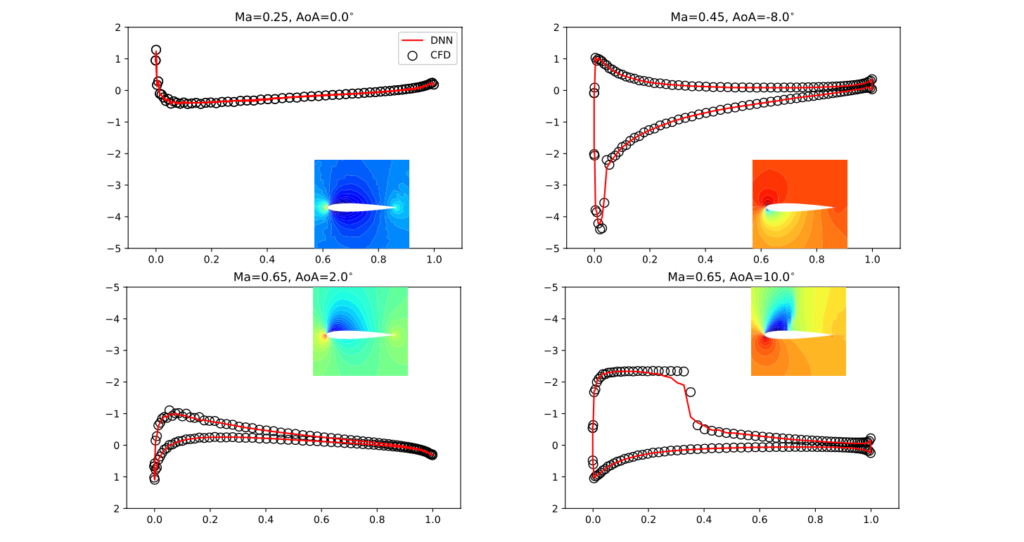
Our paper on high-accuracy airfoil flow predictions (Reynolds-averaged Navier-Stokes) with deep neural networks is online now. Interestingly, turns out you don’t need things like complex graph neural networks to handle adaptive / changing meshes. The preprint is available on arXiv: https://arxiv.org/abs/2109.02183
Even the “worst case” results are very accurate, here’s an example comparison:
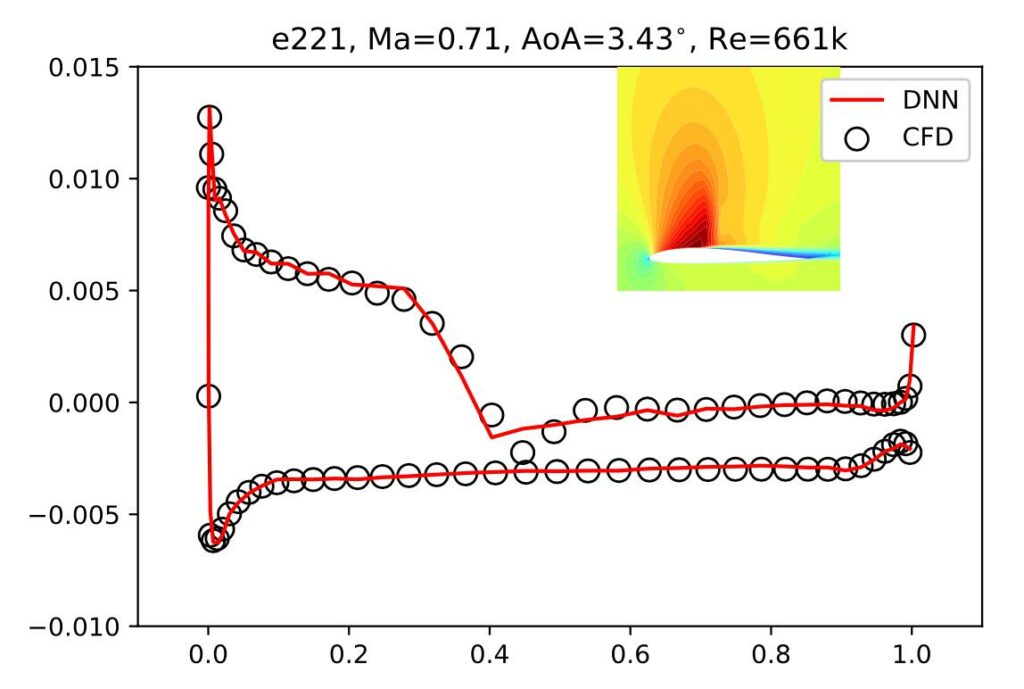
The trained neural network yields results that resolve all necessary structures such as shocks, and has an average error of less than 0.3% for turbulent transonic cases. This is appropriate for real-world, industrial applications. Here’s are the inferred skin friction coefficent for ‘e221’:
We also directly compare to a graph neural network (GNN) approach (one that is additionally coupled with a solver), yielding a ca. 3.6x improvement in terms of RMSE across all inferred fields. This is achieved with a much simpler and faster method…
Full Paper Abstract: The present study investigates the accurate inference of Reynolds-averaged Navier-Stokes solutions for the compressible flow over aerofoils in two dimensions with a deep neural network. Our approach yields networks that learn to generate precise flow fields for varying body-fitted, structured grids by providing them with an encoding of the corresponding mapping to a canonical space for the solutions. We apply the deep neural network model to a benchmark case of incompressible flow at randomly given angles of attack and Reynolds numbers and achieve an improvement of more than an order of magnitude compared to previous work. Further, for transonic flow cases, the deep neural network model accurately predicts complex flow behaviour at high Reynolds numbers, such as shock wave/boundary layer interaction, and quantitative distributions like pressure coefficient, skin friction coefficient as well as wake total pressure profiles downstream of aerofoils. The proposed deep learning method significantly speeds up the predictions of flow fields and shows promise for enabling fast aerodynamic designs.
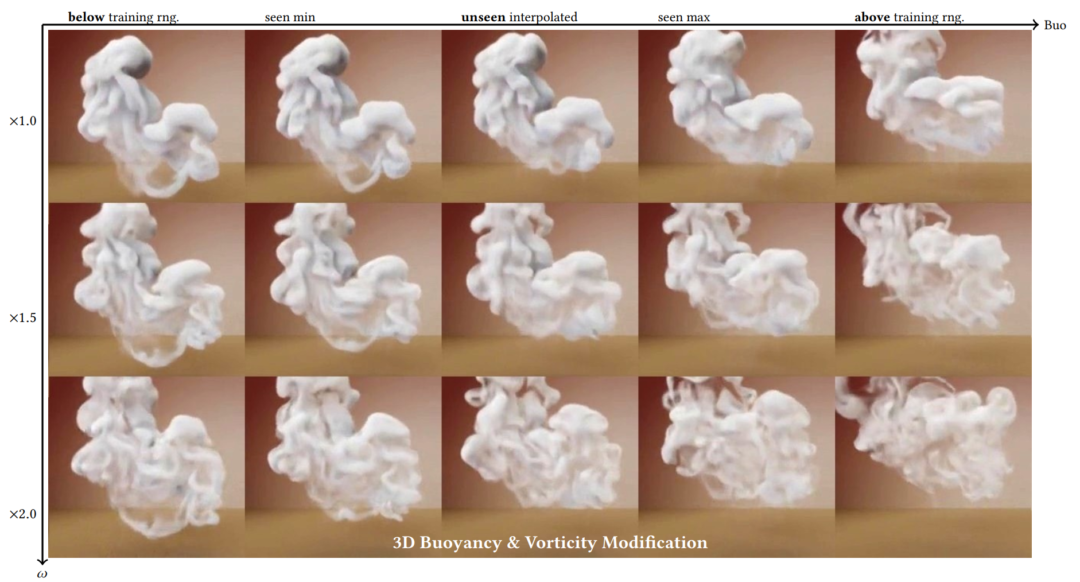
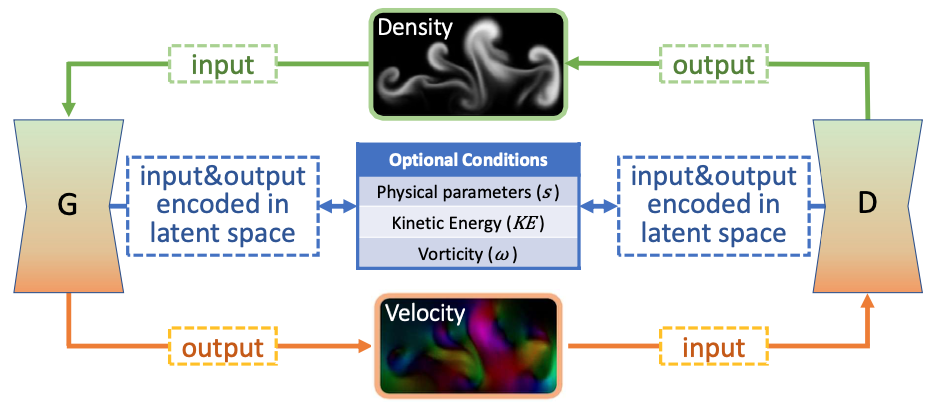
Interested in GANs that learn physical spaces and are properly conditioned by input parameters? Our SIGGRAPH paper describes how to do exactly this: https://rachelcmy.github.io/den2vel/
The learning process is enabled (among others) by a discriminator that self-supervises in terms of a physical quantity such as the marker density.
That makes it possible to obtain velocities and run a simulations purely based on a marker density. We actually couldn’t rewrite the NS equations in this way, but the generator learns it from the training data.
Full paper abstract: While modern fluid simulation methods achieve high-quality simulation results, it is still a big challenge to interpret and control motion from visual quantities, such as the advected marker density. These visual quantities play an important role in user interactions: Being familiar and meaningful to humans, these quantities have a strong correlation with the underlying motion. We propose a novel data-driven conditional adversarial model that solves the challenging, and theoretically ill-posed problem of deriving plausible velocity fields from a single frame of a density field. Besides density modifications, our generative model is the first to enable the control of the results using all of the following control modalities: obstacles, physical parameters, kinetic energy, and vorticity. Our method is based on a new conditional generative adversarial neural network that explicitly embeds physical quantities into the learned latent space, and a new cyclic adversarial network design for control disentanglement. We show the high quality and versatile controllability of our results for density-based inference, realistic obstacle interaction, and sensitive responses to modifications of physical parameters, kinetic energy, and vorticity.
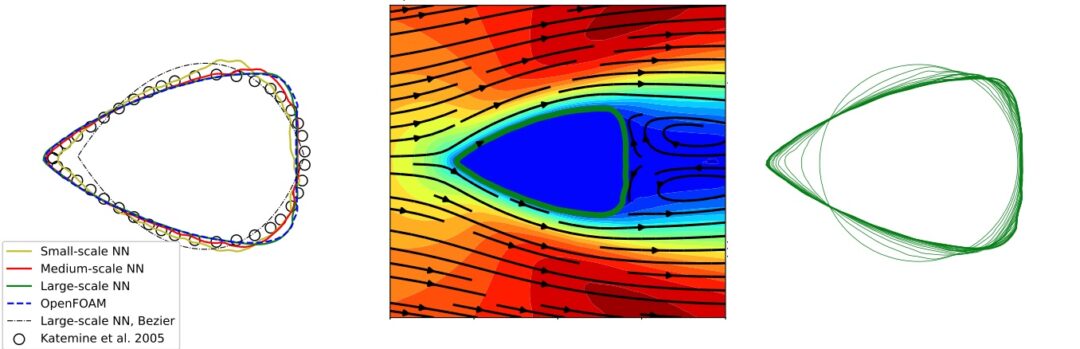
It contains everything’s that necessary to train a neural network to perform super fast shape optimizations to reduce the drag of a level-set based shape immersed in a moving fluid. The neural network is inherently differentiable, and very fast to evaluate. Hence, the trained networks represent a great building block for inverse problems. For completeness, here’s the full abstract of the paper.
Abstract: Efficiently predicting the flowfield and load in aerodynamic shape optimisation remains a highly challenging and relevant task. Deep learning methods have been of particular interest for such problems, due to their success for solving inverse problems in other fields. In the present study, U-net based deep neural network (DNN) models are trained with high-fidelity datasets to infer flow fields, and then employed as surrogate models to carry out the shape optimisation problem, i.e. to find a drag minimal profile with a fixed cross-section area subjected to a two-dimensional steady laminar flow. A level-set method as well as Bezier-curve method are used to parameterise the shape, while trained neural networks in conjunction with automatic differentiation are utilized to calculate the gradient flow in the optimisation framework. The optimised shapes and drag force values calculated from the flowfields predicted by DNN models agree well with reference data obtained via a Navier-Stokes solver and from the literature, which demonstrates that the DNN models are capable of predicting not only flowfield but also yield satisfactory aerodynamic forces. This is particularly promising as the DNNs were not specifically trained to infer aerodynamic forces. In conjunction with the fast runtime, the DNN-based optimisation framework shows promise for general aerodynamic design problems.
We’re happy to report that all three CVPR papers are online now. They cover a wide range of topics, from differentiable physics and rendering (for fluids), over learning collision free spaces (for cloth) to dynamics scenes (for neural rendering).
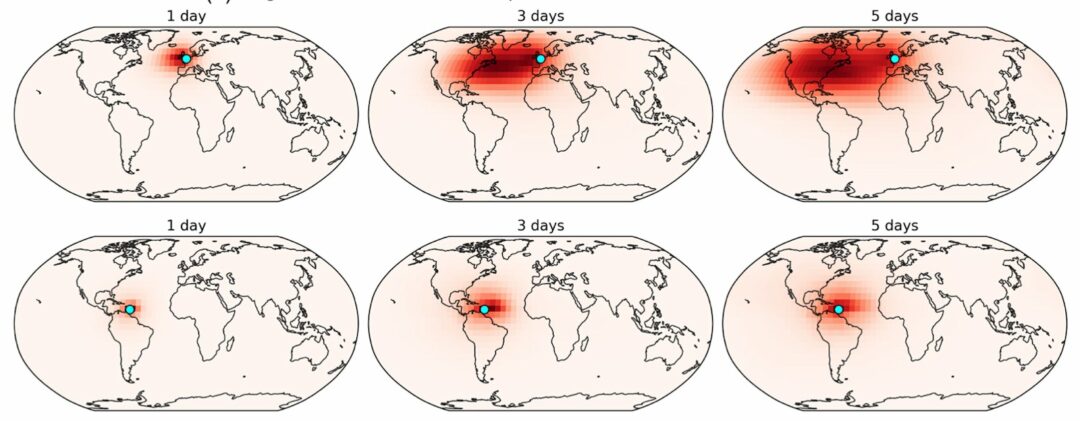
Our own entry in the WeatherBench benchmark is now published in the Journal of Advances in Modeling Earth Systems. It outperforms existing works with an RMSE of 268 and 499 for 3 and 5 day Z500 forecasts, respectively. It’s also at least on-par with a full traditional model running at a similar resolution. That being said – it’s still clearly falling behind the operational forecasting reference. Hopefully, it will inspire more people to join the WeatherBench challenge, and further improve the forecasts!
Paper Abstract: Numerical weather prediction has traditionally been based on the models that discretize the dynamical and physical equations of the atmosphere. Recently, however, the rise of deep learning has created increased interest in purely data‐driven medium‐range weather forecasting with first studies exploring the feasibility of such an approach. To accelerate progress in this area, the WeatherBench benchmark challenge was defined. Here, we train a deep residual convolutional neural network (Resnet) to predict geopotential, temperature and precipitation at 5.625° resolution up to 5 days ahead. To avoid overfitting and improve forecast skill, we pretrain the model using historical climate model output before fine‐tuning on reanalysis data. The resulting forecasts outperform previous submissions to WeatherBench and are comparable in skill to a physical baseline at similar resolution. We also analyze how the neural network makes its predictions and find that the model has learned reasonable physically reasonable correlations.
The nice image there is from our temporally-coherent fluid GAN (tempoGAN), published in 2018 at SIGGRAPH. Interestingly, since then few works were able to handle 4D data sets (3D volumes over time) while taking into account how the learned functions should change over time.
The cutout above is from our largest example, with a resolution of 1024 × 720 × 720 cells over 200 time steps. That means the CNN generated a total number of 6,794,772,480,000 cells (i.e., more than 6 trillion cells) for this sequence.
We’re happy to report that three of our papers have been accepted to the CVPR 2021 conference, two of them being orals. Details will follow in the next weeks, but as a preview we have:
Global Transport for Fluid Reconstruction with Learned Self-Supervision (oral), together with the CGL at ETH Zurich, congratulations Erik!
Neural Scene Graphs for Dynamic Scenes (oral), together with AlgoLux and the Princeton CI lab, congratulations Julian!
Self-Supervised Collision Handling via Generative 3D Garment Models for Virtual Try-On, together with the with the Multimodal Simulation Lab at Universidad Rey Juan Carlos, congratulations Igor!
Nils Thuerey recently gave a talk at the LLNL (https://www.llnl.gov/) about Differentiable Physics Simulations for Deep Learning. While we’re preparing the next release of our differentiable simulation framework PhiFlow (https://github.com/tum-pbs/PhiFlow), you can check out the talk here:
Talk abstract: In this talk I will focus on the possibilities that arise from recent advances in the area of deep learning for physical simulations. In this context, especially the Navier-Stokes equations represent an interesting and challenging advection-diffusion PDE that poses a variety of challenges for deep learning methods.
In particular, I will focus on differentiable physics solvers within the larger field of differentiable programming. Differentiable solvers are very powerful tools to guide deep learning processes, and support finding desirable solutions. The existing numerical methods for efficient solvers can be leveraged within learning tasks to provide crucial information in the form of reliable gradients to update the weights of a neural networks. Interestingly, it turns out to be beneficial to combine supervised and physics-based approaches. The former poses a much simpler learning task by providing explicit reference data that is typically pre-computed. Physics-based learning on the other hand can provide gradients for a larger space of states that are only encountered during training runs. Here, differentiable solvers are particularly powerful to, e.g., provide neural networks with feedback about how inferred solutions influence the long-term behavior of a physical model.
I will demonstrate this concept with several examples from learning to reduce numerical errors, over long-term planning and control, to generalization. I will conclude by discussing current limitations and by giving an outlook about promising future directions.
Despite being a challenging year due to various non-research related reasons (Covid, anyone?), the TUM P.B.S. group can celebrate a very successful year. We’ve had a very nice series of publications, among others with papers at the NeurIPS, ICML and ICLR conferences.
Our Paper on deep learning algorithms interacting with differentiable PDE solvers was just successfully presented at NeurIPS. And just in time for the conference, we also finished uploading the last piece of the corresponding source code release.
This is the full abstract of the paper: Finding accurate solutions to partial differential equations (PDEs) is a crucial task in all scientific and engineering disciplines. It has recently been shown that machine learning methods can improve the solution accuracy by correcting for effects not captured by the discretized PDE. We target the problem of reducing numerical errors of iterative PDE solvers and compare different learning approaches for finding complex correction functions. We find that previously used learning approaches are significantly outperformed by methods that integrate the solver into the training loop and thereby allow the model to interact with the PDE during training. This provides the model with realistic input distributions that take previous corrections into account, yielding improvements in accuracy with stable rollouts of several hundred recurrent evaluation steps and surpassing even tailored supervised variants. We highlight the performance of the differentiable physics networks for a wide variety of PDEs, from non-linear advection-diffusion systems to three-dimensional Navier-Stokes flows.
Additional details can be found on the project page.
Title: Differentiable Physics Simulations for Deep Learning Algorithms
Abstract: Differentiable physics solvers (from the broader field of differentiable programming) show particular promise for including prior knowledge into machine learning algorithms. Differentiable operators were shown to be powerful tools to guide deep learning processes, and PDEs provide a wide range of components to build such operators. They also represent a natural way for traditional solvers and deep learning methods to coexist: Using PDE solvers as differentiable operators in neural networks allows us to leverage existing numerical methods for efficient solvers, e.g., to provide reliable and flexible gradients to update the weights during a learning run.
Interestingly, it turns out to be beneficial to combine “traditional” supervised and physics-based approaches. The former poses a much more straightforward and more stable learning task by providing explicit reference data, while physics-based learning can provide gradients for a larger space of states that are only encountered at training time. Here, differentiable solvers are particularly powerful, e.g., to provide neural networks with feedback about how inferred solutions influence a physical model’s long-term behavior. I will show and discuss examples with various advection-diffusion type PDEs, among others the Navier-Stokes equations for fluids, for different learning applications. These demonstrations will highlight the properties and capabilities of PDE-powered deep neural networks and serve as a starting point for discussing future developments.