
ACM Transaction on Graphics (SIGGRAPH)
Authors
Mengyu Chu*, Technical University of Munich
You Xie*, Technical University of Munich
Jonas Mayer, Technical University of Munich
Laura Leal-Taixe, Technical University of Munich
Nils Thuerey, Technical University of Munich
(* Similar contributions)
Abstract
Our work explores temporal self-supervision for GAN-based video generation tasks. While adversarial training successfully yields generative models for a variety of areas, temporal relationships in the generated data are much less explored. Natural temporal changes are crucial for sequential generation tasks, e.g. video super-resolution and unpaired video translation. For the former, state-of-the-art methods often favor simpler norm losses such as L^2 over adversarial training. However, their averaging nature easily leads to temporally smooth results with an undesirable lack of spatial detail. For unpaired video translation, existing approaches modify the generator networks to form spatio-temporal cycle consistencies. In contrast, we focus on improving learning objectives and propose a temporally self-supervised algorithm. For both tasks, we show that temporal adversarial learning is key to achieving temporally coherent solutions without sacrificing spatial detail. We also propose a novel Ping-Pong loss to improve the long-term temporal consistency. It effectively prevents recurrent networks from accumulating artifacts temporally without depressing detailed features. Additionally, we propose a first set of metrics to quantitatively evaluate the accuracy as well as the perceptual quality of the temporal evolution. A series of user studies confirm the rankings computed with these metrics.
Code, data, models, and results are provided at https://github.com/thunil/TecoGAN.
Links![]() Preprint
Preprint![]() Code
Code![]() Video
Video![]() Supplemental webpage with additional video results
Supplemental webpage with additional video results
Example Results


Bibtex @article{chu2020tecoGAN,title="{Learning Temporal Coherence via Self-Supervision for GAN-based Video Generation (TecoGAN)}",author={Chu, Mengyu and Xie, You and Jonas Mayer and Laura Leal-Taixe and Thuerey, Nils},journal={ACM Transactions on Graphics (TOG)}, volume={39}, number={4}, year={2020}, publisher={ACM}}
Overview:
Generative adversarial networks (GANs) have been extremely suc- cessful at learning complex distributions such as natural images. However, for sequence generation, directly applying GANs without carefully engineered constraints typically results in strong artifacts over time due to the signifi- cant difficulties introduced by the temporal changes. In particular, conditional video generation tasks are very challenging learning problems where generators should not only learn to represent the data distribution of the target domain but also learn to correlate the output distribution over time with conditional inputs. Their central objective is to faithfully reproduce the temporal dynamics of the target domain and not resort to trivial solutions such as features that arbitrarily appear and disappear over time.
In our work, we propose a novel adversarial learning method for a recurrent training approach that supervises both spatial con- tents as well as temporal relationships. We apply our approach to two video-related tasks that offer substantially different challenges: video super-resolution (VSR) and unpaired video translation (UVT). With no ground truth motion available, the spatio-temporal adversarial loss and the recurrent structure enable our model to generate realistic results while keeping the gener- ated structures coherent over time. With the two learning tasks we demonstrate how spatio-temporal adversarial training can be employed in paired as well as unpaired data domains. In addition to the adversarial network which supervises the short-term temporal coherence, long-term consistency is self-supervised using a novel bi-directional loss formulation, which we refer to as “Ping-Pong” (PP) loss in the following. The PP loss effectively avoids the temporal accumulation of artifacts, which can potentially benefit a variety of recurrent architectures. We also note that most existing image metrics focus on spatial content only. We fill the gap of temporal assessment with a pair of metrics that measures the perceptual sim- ilarity over time and the similarity of motions with respect to a ground truth reference. User studies confirm these metrics for both tasks.
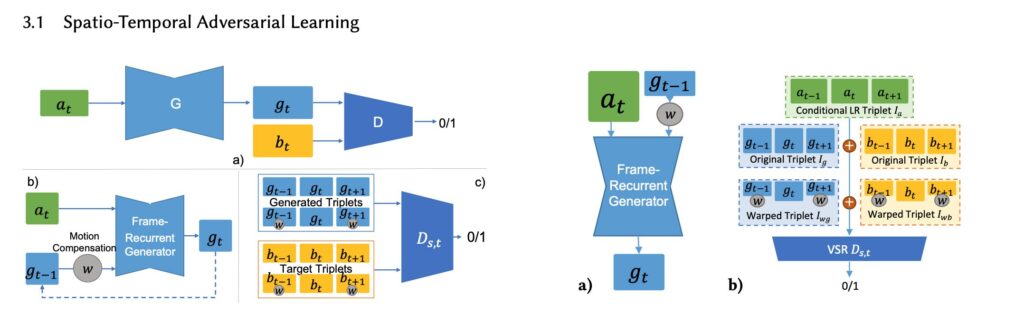
The central contributions of our work are:
- a spatio-temporal discriminator unit together with a careful analysis of training objectives for realistic and coherent video generation tasks,
- a novel PP loss supervising long-term consistency,
- in addition to a set of metrics for quantifying temporal coherence based on motion estimation and perceptual distance.
Together, our contributions lead to models that outperform previous work in terms of temporally-coherent detail, which we qualitatively and quantitatively demonstrate with a wide range of content.