Learning Temporal Coherence via Self-Supervision
for GAN-based Video Generation
The Supplemental Web-Page
We provide code, data, models, and results at https://github.com/thunil/TecoGAN.
The project page is at https://ge.in.tum.de/publications/2019-tecogan-chu/.
Video results are organized in form of this html page, so that indidividual scenes can be watched repeatedly as many times as necessary to assess the different version.
Please click on each scene to play the corresponding video.
This document contains the following chapters:
1. Overview
2. Results
3. Evaluations
4. Loss Ablation Study
5. Adversarial Equilibrium
6. tOF Visualization
7. Triplet Visualization
1. Overview
We propose a method for the temporal self-supervision of GAN-based video generation tasks.
In paired as well as unpaired data domains, we find that temporal adversarial learning is the key to
achieving temporally coherent solutions without sacrificing spatial detail.
Below, we show results for video super-resolution (VSR) and unpaired video translation (UVT) tasks.
For VSR, even under-resolved structures in the input can lead to realistic and coherent outputs with the help of our temporal supervision.
Bridge scene from Tears of Steel. Left: Low-Resolution Input, right: TecoGAN Output.
For UVT, our model can learn temporal and spatial consistency simultaneously. It generates realistic details that change naturally over time.
(Input) Trump to Obama (TecoGAN Output)
(Input) Obama to Trump (TecoGAN Output)
(Input) LR Smoke to HR Smoke (TecoGAN Output)
(Input) Smoke Simulations to Real Captures (TecoGAN)
2. Results
2.1 VSR comparisons
Comparison with previous work (DUF, RBPN and EDVR*, Fig.1 and Fig.12 of the paper)
* Note that EDVR is trained and evaluated using bicubic down-sampled inputs, while all others take inputs with Gaussian blur. With a standard deviation of 1.5, the gaussian blurred inputs usually have less high-frequency details comparing to bicubic down-sampling. Thus, EDVR has a slightly easier task and receives an input with more detailed content.
2.2 UVT comparisons
Smoke comparison with previous work (CycleGAN, Fig.8 of the paper)


Face comparison with previous work (CycleGAN and RecycleGAN, Fig.8 of the paper, 0.5x speed)
Inputs
CycleGAN
RecycleGAN
STC-V2V [Park et al.]
TecoGAN
While the CycleGAN model collapses to essentially static outputs for Obama, TecoGAN offers spatial details on par with CycleGAN and temporal consistency on par with RecycleGAN. Note the detailed skin texture of the synthesized Obama, and blinking motions of the synthesized Trump for TecoGAN.
3. Evaluations
3.1 Calendar & Foliage results (Fig.6, 7 in the paper)
3.2 VSR Metrics & User Studies (Tab.2, 5 and Fig.20 in the paper)
| VSR | Calendar | Foliage | ||||
|---|---|---|---|---|---|---|
| methods | FRVSR | DUF | TecoGAN | FRVSR | DUF | TecoGAN |
| PSNR↑ | 23.94 | 24.16 | 23.28 | 26.35 | 26.45 | 24.26 |
| LPIPS↓ | 0.2976 | 0.3074 | 0.1515 | 0.3242 | 0.3492 | 0.1902 |
| tLP↓ | 0.01064 | 0.01596 | 0.0178 | 0.01644 | 0.02034 | 0.00894 |
| tOF↓ | 0.1552 | 0.1146 | 0.1357 | 0.1489 | 0.1356 | 0.1238 |
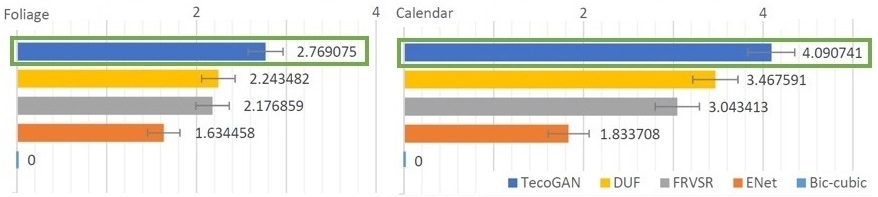
From the scores of our user studies shown above, we can see that TecoGAN is the method preferred by users.
This confirms our metric evaluations (shown on the left):
By keeping its temporal coherence on par with non-adversarial models,
but at the same time generating more realistic detail,
TecoGAN is stays closer to the reference than other methods.
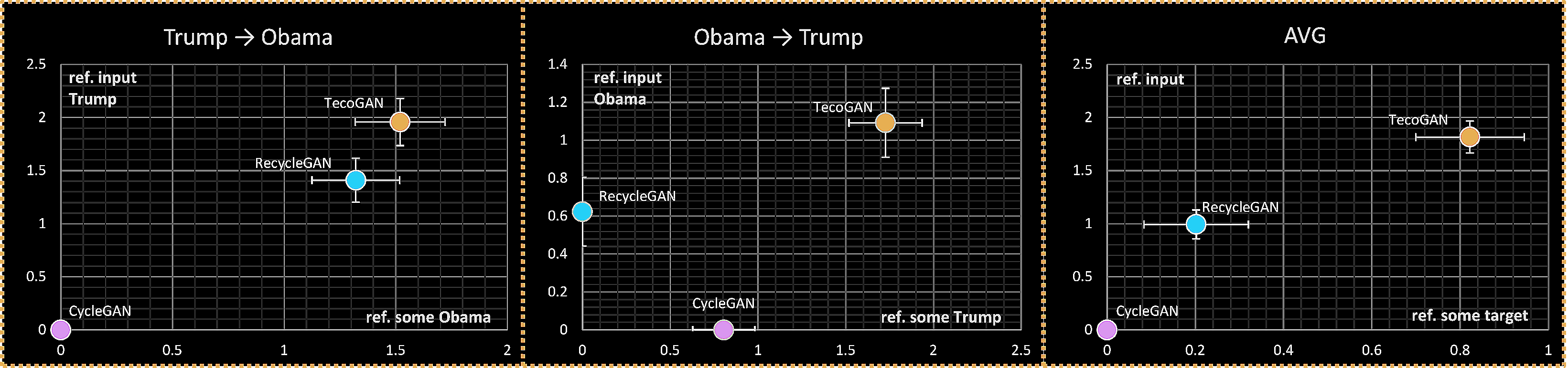
3.3 UVT Metrics & User Studies (Tab.3 and Fig.21 in the paper)
With no ground-truth data available, spatial metrics cannot be evaluated for UVT tasks. We evaluate tOF and tLP using the motion and the perceptual changes from the input data. Here we show the evaluation on the Obama&Trump dataset. tOF is less informative as it unnecessarily requires pixel-wise aligned motions. TecoGAN achieves good tLP scores via its temporal coherence, on par with RecycleGAN, and its spatial detail is on par with CycleGAN.
| UVT [tLP↓ tOF↓] | Trump→Obama | Obama→Trump | AVG |
|---|---|---|---|
| CycleGAN | [0.0176, 0.7727] | [0.0277, 1.1841] | [0.0234, 0.9784] |
| RecycleGAN | [0.0111, 0.8705] | [0.0248, 1.1237] | [0.0179, 0.9971] |
| TecoGAN | [0.0120, 0.6155] | [0.0191, 0.7670] | [0.0156, 0.6913] |
The ranking of the metrics is confirmed by the following user studies, where the TecoGAN model is consistently prefered by the participants.
4. Loss Ablation Study
(Fig.5-9 and Sec.4 in the paper, please view full-screen)
4.1. ENet V.S. DsOnly. Recurrent image generation of DsOnly leads to better temporal coherence.
4.2. Temporal adversarial learning of DsDt improves temporal consistency.
4.3. The Ping-Pong loss (on the right) effectively avoids the temporal accumulation of invalid features,
which usually happen in recurrent networks(on the left).
4.4. The results of DsDtPP shown on the left were achieved
only after numerous runs manually balancing the discriminators. Instead the
spatio-temporal adversarial learning (right) uses fewer resources and offers more stable training
with high quality synthesis.
4.5. In the proposed PP loss, both the Ping-Pang sequence data augmentation and its temporal constrains contribute to preventing temporal streaking artifacts.
In order to seperate their contributions, we train a PP-Augment model with the bi-directional PP sequence without an $L^2$ constraint (i.e., $\lambda_p=0$ in the $\mathcal{L}_{G,F}$ row of Table 1).
While DsDt (denoted as "Without PP" above) shows strong recurrent streaking artifacts early on (from frame 15), the PP augmentation version ("PP-Augment") slightly reduces these artifacts, which become noticeable from ca. frame 32 on. Only our regular model with the full PP loss ("Full PP", TecoGAN-) successfully avoids temporal accumulation for all 40 frames (and longer). Thus, the temporal constraint of the PP loss is crucial for avoiding visual artifacts and performs better than only training with longer sequences.
4.6. The full model with a larger generator on the right leads to improved generation of detail:
|
|
4.7. The UVT task yields similar conclusions to the VSR ablation above: While DsOnly can improve the temporal coherence by relying on the frame-recurrent input, temporal adversarial learning in Dst and TecoGAN is the key to a correct spatio-temporal cycle consistency. Without PP loss, Dst shows undesirable smoke in empty regions. The full TecoGAN model can avoid such artificial temporal accumulation. (0.5x speed) |
|
|
The UVT DsDtPP model contains two generators and four discriminator networks, and is very difficult to balance in practice. By weighting the temporal adversarial losses from Dt with 0.6 and the spatial one from Ds with 1.0, the DsDtPP model can yield a similar performance to the Dst model (on the right). The proposed Dst architecture is the better choice in practice, as it learns a natural balance of temporal and spatial components by itself, and requires fewer resources. |


| DsOnly also shows coherent but undesirable motion, e.g. on Obama's right collar. His eyes barely blink, indicating that spatio-temporal cycle consistency cannot be properly established without temporal supervision. |
5. Spatio-temporal Adversarial Equilibrium Analysis
Input Ablation for UVT Dst (Fig.8 and Sec.4 in the paper, 0.5x speed)
Baseline:
3 original frames
3 original frames
vid2vid [Wang2018] variant :
3 original frames + estimated motions
3 original frames + estimated motions
Concat version:
3 original frames + 3 warped frames
3 original frames + 3 warped frames
TecoGAN: {current frame}x3 OR
3 warped frames OR 3 original frames
3 warped frames OR 3 original frames
It is hard for the baseline model and the vid2vid variant to learn the complex temporal dynamics of the references. While the warped frames help the concat version to improve results, the full TecoGAN model performs even better. Via the proposed curriculum learning approach, it arrives at a better equilibrium as its discriminator can focus on spatial features first. It learns the spatio-temporal correlation from the original triplets towards the end of a training run.
6. tOF Visualization
Here, we show the optical flow between frames of the armor scene on the left and in the middle. While the optical flow of ENet is very noisy, the results of DUF and TecoGAN are closer to the ground truth (GT). The per-pixel differences to the ground truth of DUF and TecoGAN are shown on the right. DUF shows larger errors on the chest, conforming to the temporal inconsistencies (drifting) we see in the armor video clip above. Values are shown in HSV color space, with H (hue) representing directions, S (Saturation) being constant, and V (light) representing the l1 vector norm.
7. Triplet Visualization
The following videos provide an intuiton for why the proposed curriculum learning for UVT is important to leverage our spatio-temporal discriminators. The different types of triplets differ in what information they provide for learning.
Original triplets |
|



Warped triplets |
Next, we highlight several regions of the content of the corresponding warped triplets.
In the warped triplets, the eyebrows, eyes, noses and mouths are better aligned.
This can make the job easier for discriminators by supplying information “in-place” wherever possible.
However, since the flow estimator F is mainly trained to align natural images and the estimated motion fields
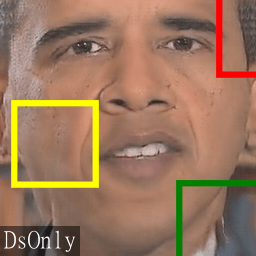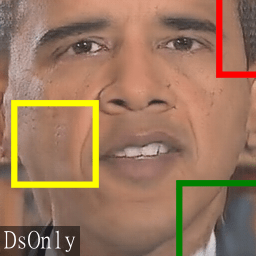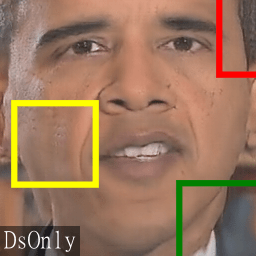
contain approximation errors, the unatural collar motion (green box) of the DsOnly results cannot be compensated. With a better alignment, these subtle changes are easier to be detected.
Likewise for the jittering of the hair (red box)
and flickering motions on the cheek (yellow box) in the DsOnly results.
These artifacts are successfully removed in the TecoGAN results.
|
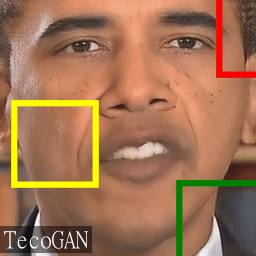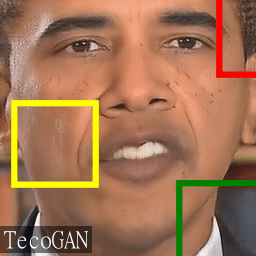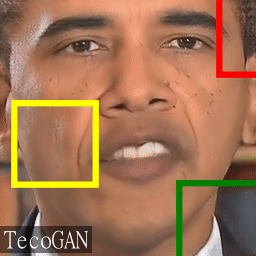

In the warped triplets we can also see that there are natural "in-place" changes,
such as the illumination changes on the nose (white ellipse), the occurrence of teeths and tongue,
and tissue/wrinkles softening and hardening because of speaking.
By supervising via all three versions of the triplets, i.e, the original, warped, and static versions, the spatio-temporal discriminator can guide the generator to infer realistic spatial features with natural motions.
The warped triplets are very helpful for discriminators to check wheter the spatial features in a given place are consistent.
With the differentiable warping, the gradients can be back-propagated to the "original" pixels in different positions of the original frames.
Below we show the same sample as above on the left as A, and a new sample B on the right for all triplets variants (from left to right, the original, warped and static triplets) :
| Original A | Warped A | Static A | Original B | Warped B | Static B | |
| DsOnly Generated Triplets |
 |
 |
||||
| TecoGAN Generated Triplets |
 |
 |
||||
| Ground-Truth Selected Triplets |
 |
 |
||||