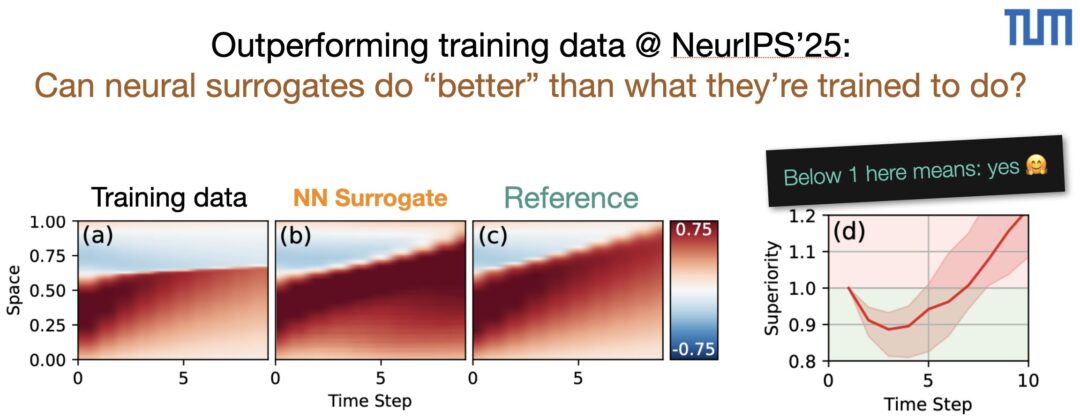
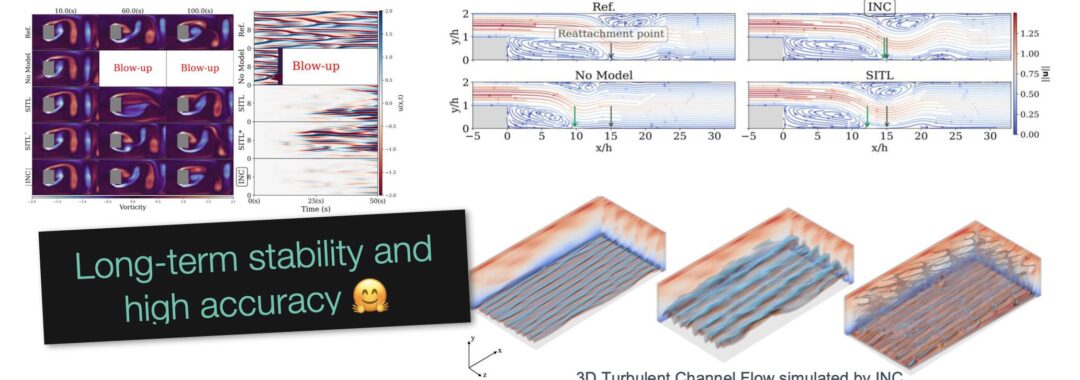
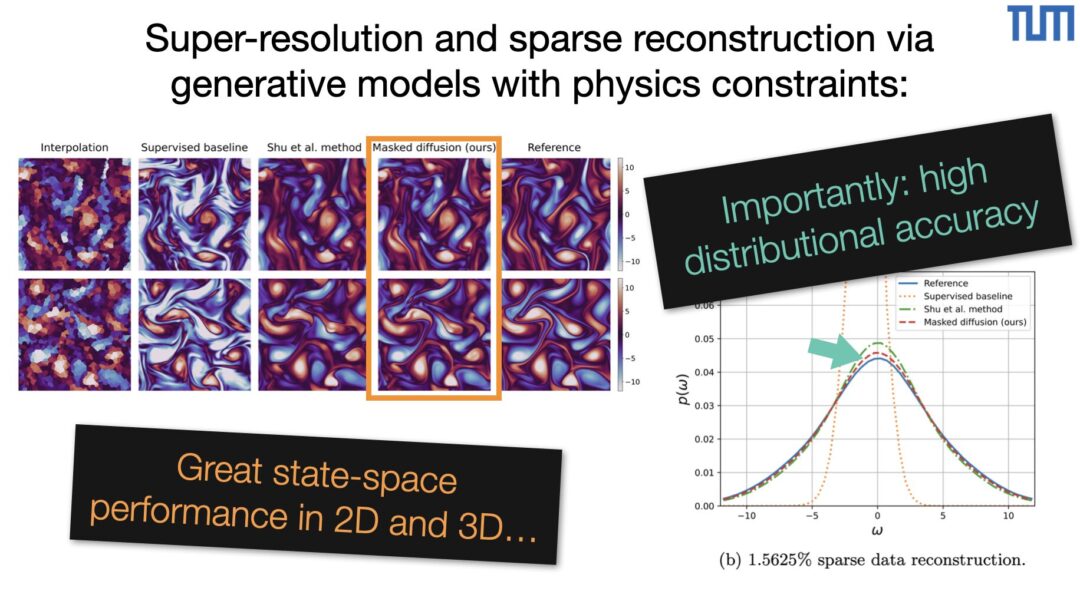
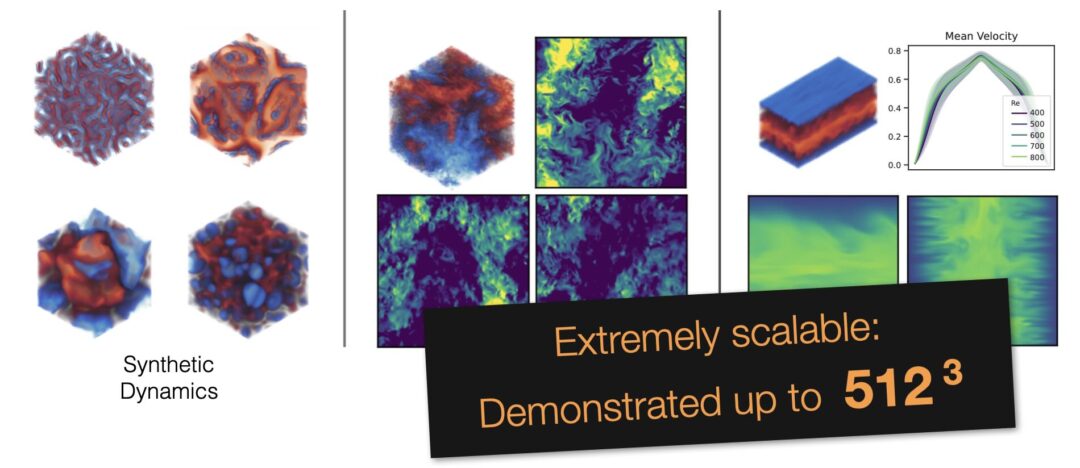
Congratulations to Hao for his ICML Oral on rotationally equivariant transformers: https://tum-pbs.github.io/revit-web/ 👍
Physical systems obey rotational symmetries, but transformer architectures used for scientific ML (and in vision) surprisingly do not enforce them. In our ICML paper “Rotational-equivariant Vision Transformers for PDEs” (ReVit), we introduce a first vision-transformer framework for grid-based PDE solvers that achieves exact equivariance for discrete rotations and strong robustness to continuous rotations. The key idea is to transform physical fields into local canonical coordinate systems, enabling standard self-attention while preserving physical symmetries.
Across a wide range of benchmarks (turbulent channel flows & 3D magnetohydrodynamics) ReViT consistently improves accuracy, reduces rotational errors, and achieves up to 65% lower MSE than strong transformer and neural operator baselines.
Our results suggest that building rotational-equivariance directly into transformer architectures can substantially improve generalization and efficiency of scientific foundation models.
Paper link: https://ge.in.tum.de/download/wei-icml2026-revit.pdf
Full abstract: Physics obeys strict symmetries like rotational equivariance. However, the standard Transformer architectures widely used in physics foundation models do not enforce these constraints by construction. We introduce ReViT, a rotationally equivariant Vision Transformer framework for neural PDE solvers operating on grid-based physical fields \crr{that achieves exact equivariance for the discrete groups $C_4$ (2D) and the chiral octahedral group $O$ (3D), with bounded approximate SO(d) equivariance for continuous rotations.} ReViT maps scalar and vector inputs into locally invariant representations derived from physics-based canonical bases, enabling the use of standard self-attention without symmetry violations. Built on a hierarchical Swin-style backbone with a precomputed reference basis pyramid, ReViT preserves equivariance across multi-scale operations. We evaluate ReViT on a wide range of 2D and 3D PDE benchmarks, such as Magnetohydrodynamics and Turbulent Channel Flows, demonstrating significant gains over state-of-the-art baselines. ReViT exhibits strong generalization, and reduces MSE by up to 65% compared with the best-performing alternatives.