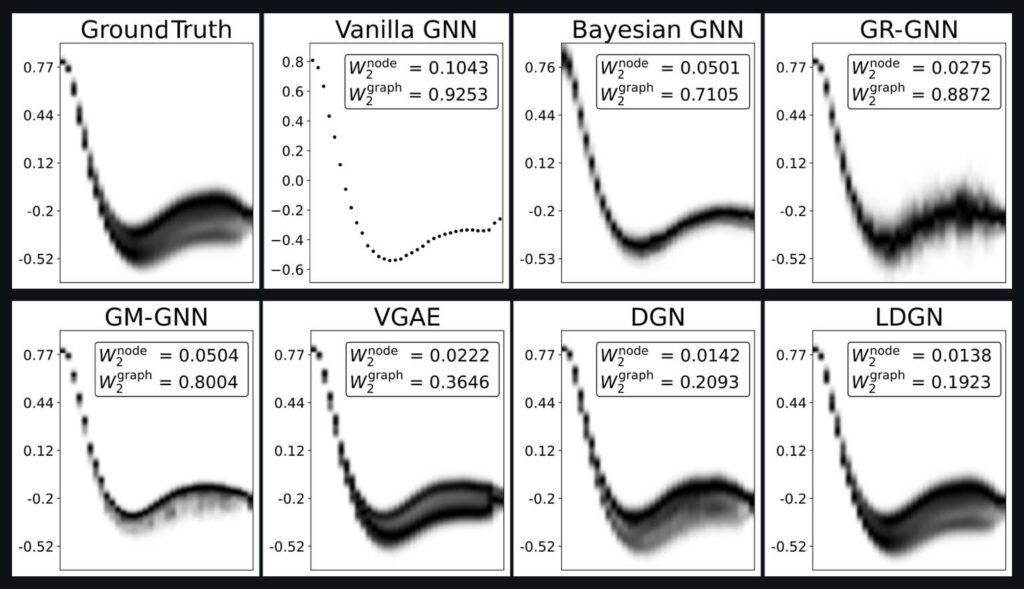
Bjoern’s paper on equivariant GraphNets was accepted now at Physics of Fluids 👍 , you can check it out at: https://doi.org/10.1063/5.0279499 (Rotational Equivariant Graph Neural Networks via local Eigenbasis Transformations)
The core idea is a very generic and powerful one: we compute a local Eigenbasis from flow features for equivariance. Mathematically it’s identical to previous approaches, but much faster (and simpler 😅)
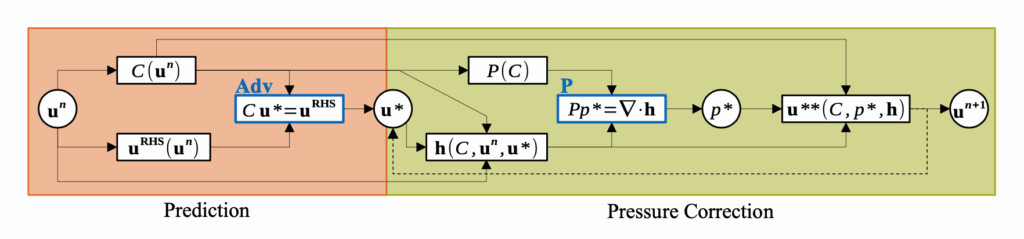
Full abstract: Rotational equivariance arises in physical problems as a common symmetry of partial differential equations, including the Navier–Stokes equations governing fluid phenomena. Architectural changes are necessary when guaranteeing rotational equivariance in neural networks, which incur additional computational costs, leading to increased inference times by up to an order of magnitude, as measured in our numerical studies. We introduce a new method for rotational equivariance in graph neural networks that achieves high predictive accuracy while maintaining a smaller computational footprint than comparable approaches. We establish rotational equivariance by transforming vector features and spatial neighborhood information into local, node-specific vector bases. The resulting architecture follows an encode-process-decode paradigm. Vector features are transformed before being encoded. When message-passing, i.e., in the process stage, latent features are interpreted as a set of vectors and undergo a similar transformation and are thus always processed in the receivers’ basis. The results are transformed back into the reference system after decoding, resulting in rotational equivariance. The networks receive full physical and geometric information of the neighborhood without costly computations. Three different scenarios are experimentally investigated, ranging from an advection problem to incompressible Navier–Stokes flow around an ellipse and to a highly complex transonic cylinder flow scenario. We compare with state-of-the-art approaches and demonstrate how our method achieves comparable accuracy while reducing computational costs. Our method is the only one to consistently improve upon a data-augmentation baseline, and does so with an error reduction of 25.3%. It is 1.6 times faster than the next best model that guarantees equivariance.