We’re happy to report two accepted papers at ICLR 2024! Congrats Patrick and Rene 😀 👍 They’re on particle-based learning https://openreview.net/forum?id=HKgRwNhI9R and stabilized backprop through time https://openreview.net/forum?id=bozbTTWcaw, additional details, code etc. will follow soon. For now here are the two abstracts in full:
Symmetric Basis Convolutions for Learning Lagrangian Fluid Mechanics: Learning physical simulations has been an essential and central aspect of many recent research efforts in machine learning, particularly for Navier-Stokes-based fluid mechanics. Classic numerical solvers have traditionally been computationally expensive and challenging to use in inverse problems, whereas Neural solvers aim to address both concerns through machine learning. We propose a general formulation for continuous convolutions using separable basis functions as a superset of existing methods and evaluate a large set of basis functions in the context of (a) a compressible 1D SPH simulation, (b) a weakly compressible 2D SPH simulation, and (c) an incompressible 2D SPH Simulation. We demonstrate that even and odd symmetries included in the basis functions are key aspects of stability and accuracy. Our broad evaluation shows that Fourier-based continuous convolutions outperform all other architectures regarding accuracy and generalization. Finally, using these Fourier-based networks, we show that prior inductive biases, such as window functions, are no longer necessary.
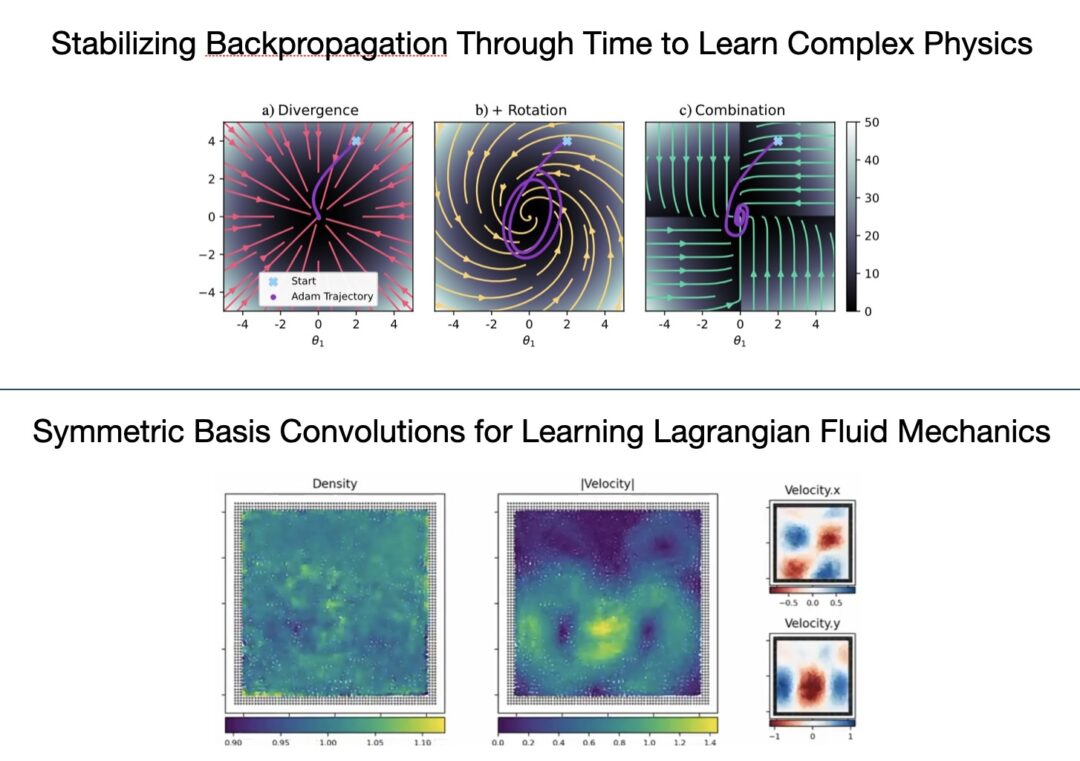
Stabilizing Backpropagation Through Time to Learn Complex Physics: Of all the vector fields surrounding the minima of recurrent learning setups, the gradient field with its exploding and vanishing updates appears a poor choice for optimization, offering little beyond efficient computability. We seek to improve this suboptimal practice in the context of physics simulations, where backpropagating feedback through many unrolled time steps is considered crucial to acquiring temporally coherent behavior. The alternative vector field we propose follows from two principles: physics simulators, unlike neural networks, have a balanced gradient flow and certain modifications to the backpropagation pass leave the positions of the original minima unchanged. As any modification of backpropagation decouples forward and backward pass, the rotation-free character of the gradient field is lost. Therefore, we discuss the negative implications of using such a rotational vector field for optimization and how to counteract them. Our final procedure is easily implementable via a sequence of gradient stopping and component-wise comparison operations, which do not negatively affect scalability. Our experiments on three control problems show that especially as we increase the complexity of each task, the unbalanced updates from the gradient can no longer provide the precise control signals necessary while our method still solves the tasks.