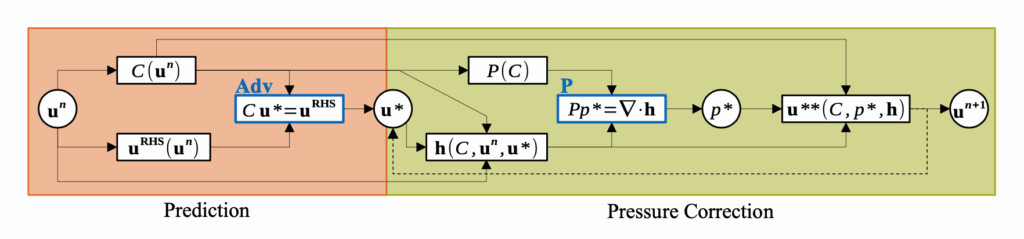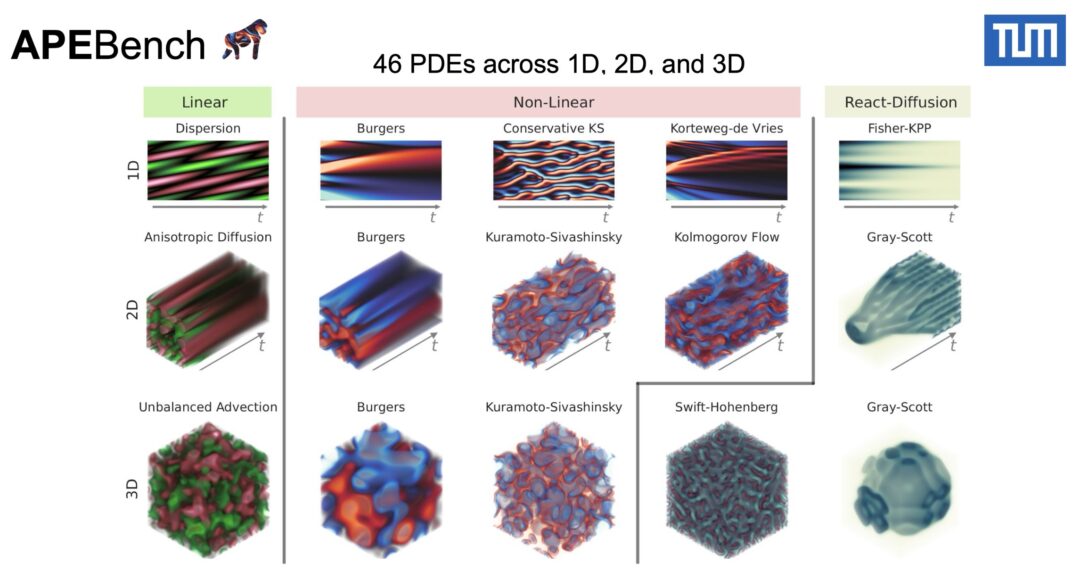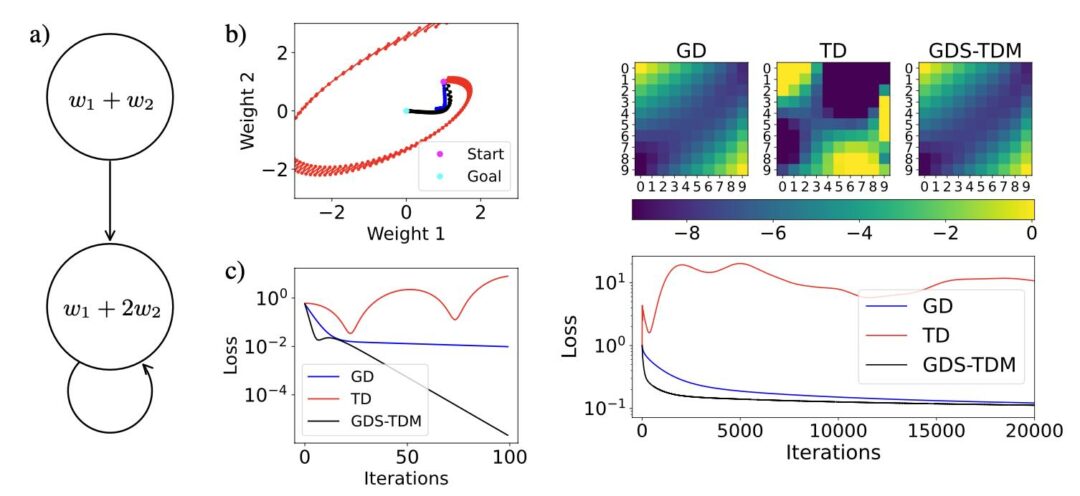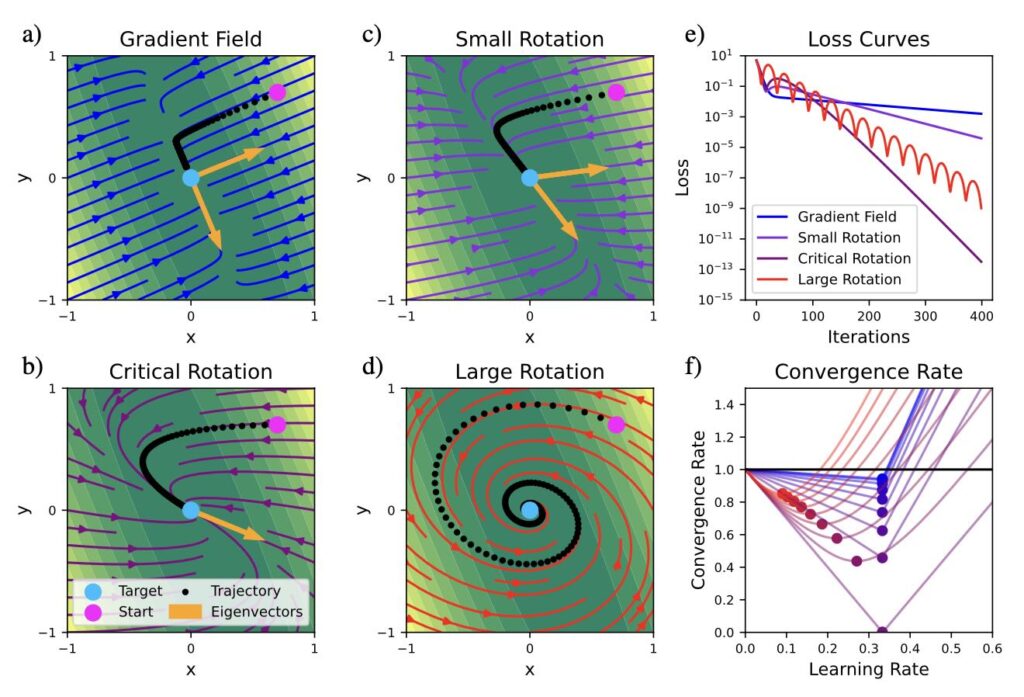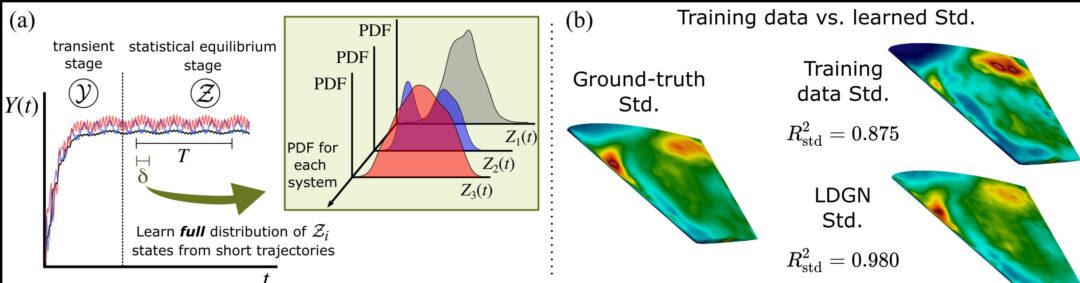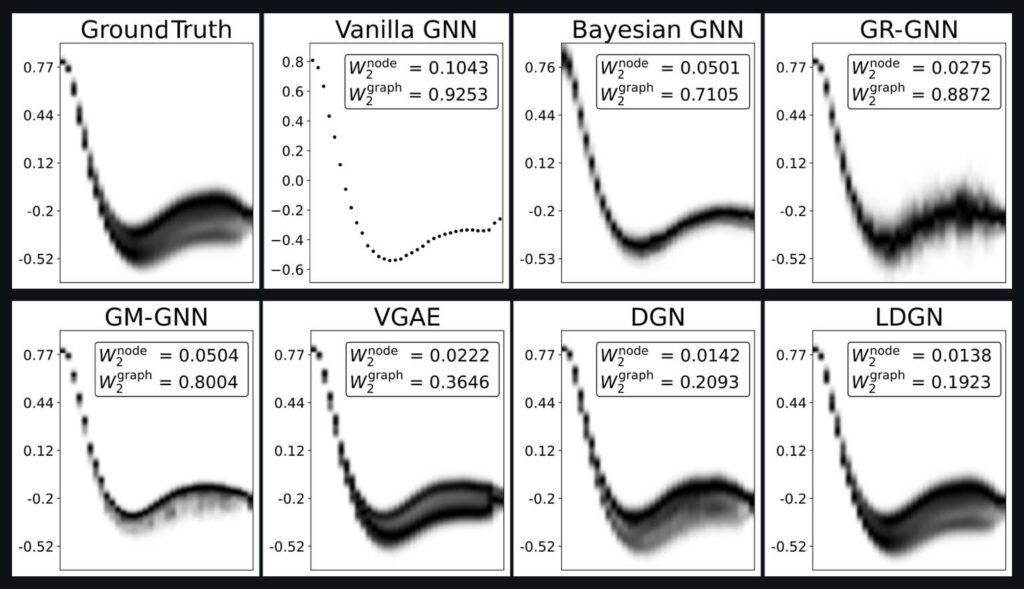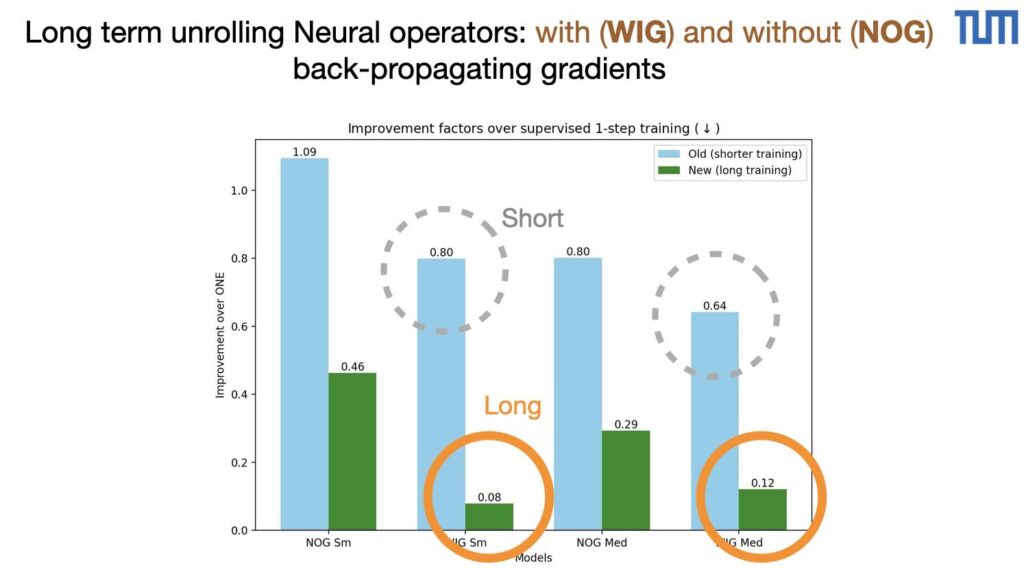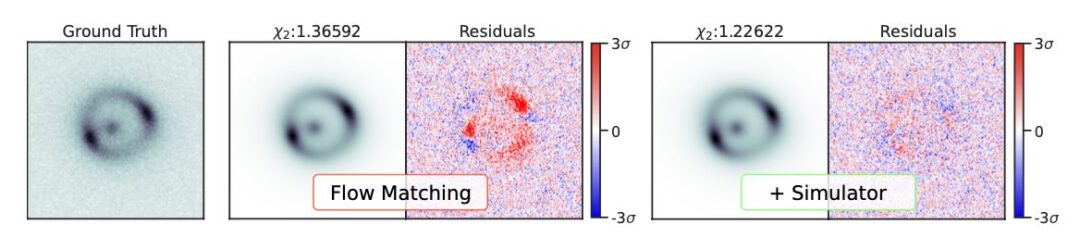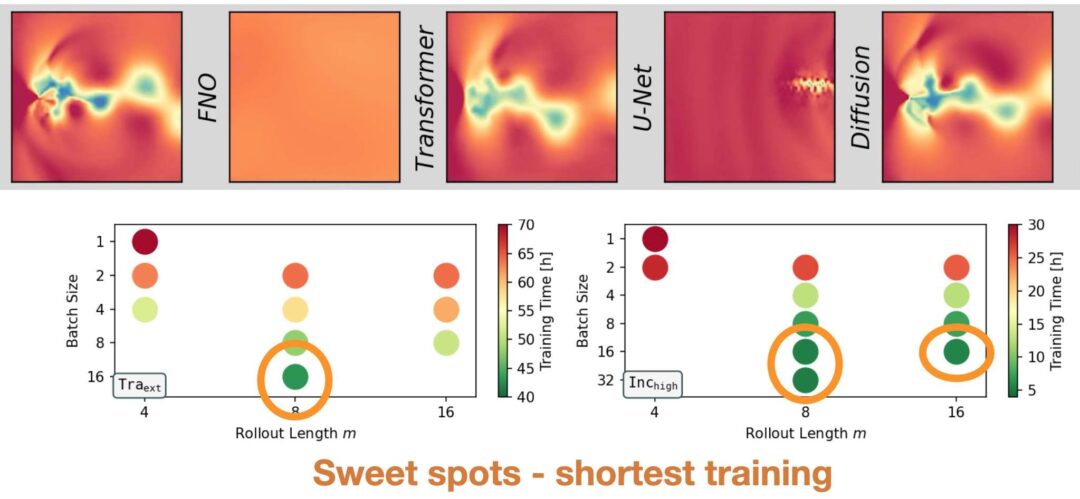
Our paper detailing the differentiable SPH solver by Rene is online now on arxiv: https://arxiv.org/abs/2507.21684 If you’re interested in fast and efficient neighborhoods, differentiable SPH operators and neat first optimization and learning tasks, please take a look!
Title: diffSPH: Differentiable Smoothed Particle Hydrodynamics for Adjoint Optimization and Machine Learning
Full paper abstract: We present diffSPH, a novel open-source differentiable Smoothed Particle Hydrodynamics (SPH) framework developed entirely in PyTorch with GPU acceleration. diffSPH is designed centrally around differentiation to facilitate optimization and machine learning (ML) applications in Computational Fluid Dynamics~(CFD), including training neural networks and the development of hybrid models. Its differentiable SPH core, and schemes for compressible (with shock capturing and multi-phase flows), weakly compressible (with boundary handling and free-surface flows), and incompressible physics, enable a broad range of application areas. We demonstrate the framework’s unique capabilities through several applications, including addressing particle shifting via a novel, target-oriented approach by minimizing physical and regularization loss terms, a task often intractable in traditional solvers. Further examples include optimizing initial conditions and physical parameters to match target trajectories, shape optimization, implementing a solver-in-the-loop setup to emulate higher-order integration, and demonstrating gradient propagation through hundreds of full simulation steps. Prioritizing readability, usability, and extensibility, this work offers a foundational platform for the CFD community to develop and deploy novel neural networks and adjoint optimization applications.