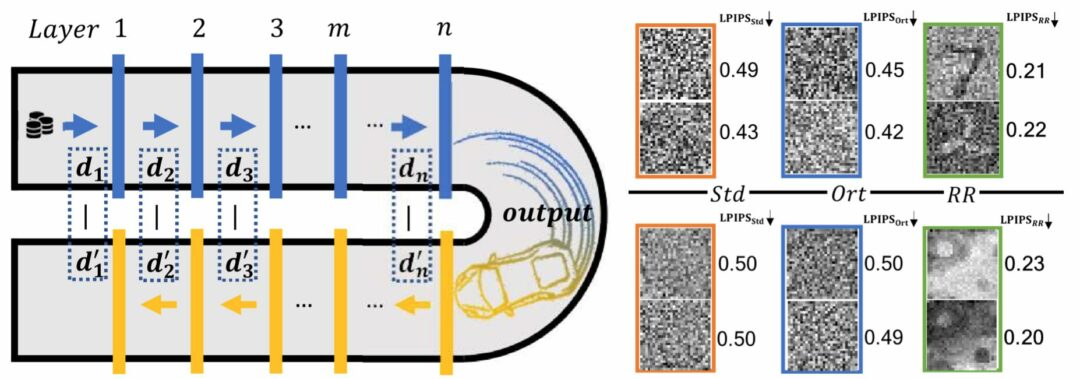
Our paper on improving neural network generalization via a forward-backward pass is also finally online, together with a first code example. A common question that we get about this project: “why racecar“? This is worth explaining here in a bit more detail: it’s not about the speed of the method, but rather racecar is a nice palindrome. Hence, if you reverse the word, you still have “racecar”. Our training approach also makes use of a reversed neural network architecture, re-using all existent building blocks of the network and their weights, somewhat similar to a palindrome. Hence the name. Interestingly, this reverse structure yields an embedding of singular vectors into the weight matrices, and improves performance for new tasks, as we show for a variety of classification and generation tasks in our paper.
Paper Abstract:
We propose a novel training approach for improving the generalization in neural networks. We show that in contrast to regular constraints for orthogonality, our approach represents a data-dependent orthogonality constraint, and is closely related to singular value decompositions of the weight matrices. We also show how our formulation is easy to realize in practical network architectures via a reverse pass, which aims for reconstructing the full sequence of internal states of the network. Despite being a surprisingly simple change, we demonstrate that this forward-backward training approach, which we refer to as racecar training, leads to significantly more generic features being extracted from a given data set. Networks trained with our approach show more balanced mutual information between input and output throughout all layers, yield improved explainability and, exhibit improved performance for a variety of tasks and task transfers.