We typically focus on deep-learning methods for physical data, with a particular emphasis on Navier-Stokes & fluids. However, beyond latent-space simulation algorithms and learning with differentiable solvers, generative models have also been a central theme of our work.
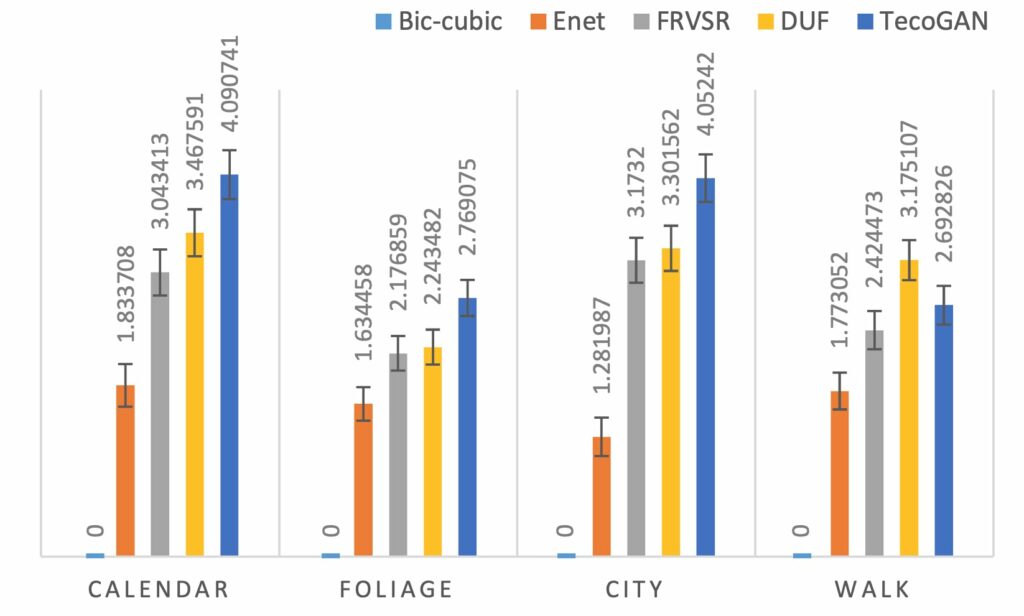
Motivated by time-dependent problems from the physics area, we especially focus on spatio-temporal data such as videos. Here, self-supervision in space, as well as time, has shown lots of promise, e.g., in the form of the TecoGAN model, which can handle video super-resolution and unpaired video translation, among others. This is the video of a talk given at the CLIP workshop at CVPR 2020, where we demonstrate generative adversarial networks for video super-resolution, as well as unpaired video translation. In addition, we’ve targeted improved evaluation metrics for video content. In particular, Nils highlights our choice of a perceptual metric (such as LPIPS), in addition to a temporal perceptual evaluation (tLP) and a motion estimate (tOF). We’ve tested these across a range of examples and verified their rankings with user studies.
Here you can see a part of the perceptual evaluation from our user studies:
Further details:
– Talk on YouTube
– Learning Temporal Coherence via Self-Supervision for GAN-based Video Generation (TecoGAN)
– TecoGAN source code