We recently re-ran some of the KS equation tests in our “unrolling” paper (Differentiability in Unrolled Training of Neural Physics Simulators on Transient Dynamics , https://github.com/tum-pbs/unrolling), and interestingly the effects are even stronger with long training, i.e. training until full convergence of the CNN-based operators.
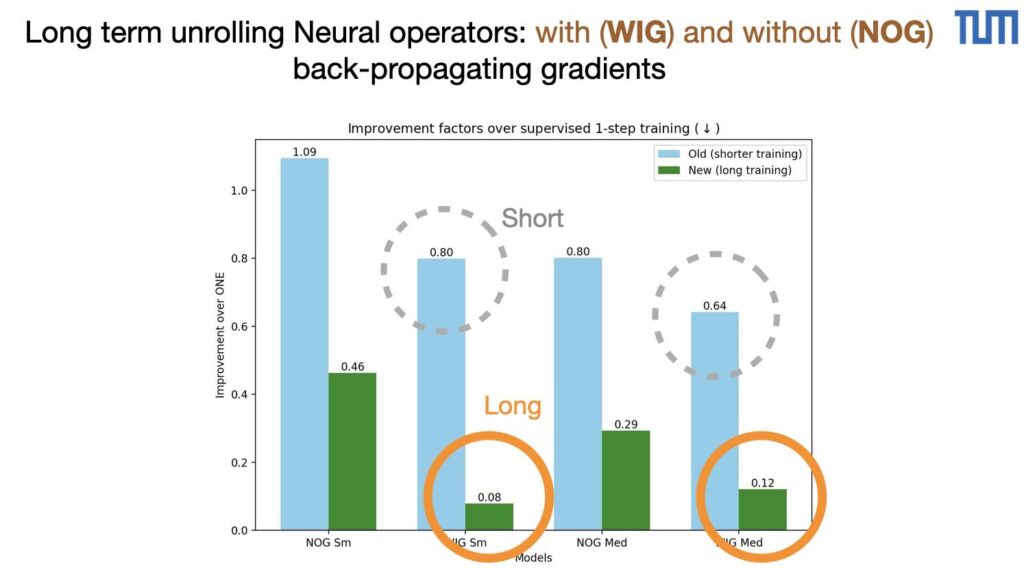
The improvements are larger overall, the no-gradient (NOG) variant shows improvements of 0.46 and 0.29 for the small and medium sized models. It’s even more prominent for the with-gradient (WIG) case, i.e. full unrolling with back-propagation: the improvements are up to 10x!
Here are the full numbers for mean relative errors measured over 40 tests, with standard deviations over model initializations:
OLD Runs (20 epochs)
model ONE-26,8 = 0.00728 +/- 0.002
model NOG-26,8 = 0.00797 +/- 0.002
model WIG-26,8 = 0.00582 +/- 0.002
model ONE-52,12 = 0.00318 +/- 0.002
model NOG-52,12 = 0.00255 +/- 0.001
model WIG-52,12 = 0.00204 +/- 0.000NEW (80 epochs with Plateau scheduler)
model ONE-26,8 = 0.00190 +/- 0.000
model NOG-26,8 = 0.00088 +/- 0.000
model WIG-26,8 = 0.00015 +/- 0.000
model ONE-52,12 = 0.00099 +/- 0.000
model NOG-52,12 = 0.00029 +/- 0.000
model WIG-52,12 = 0.00012 +/- 0.000