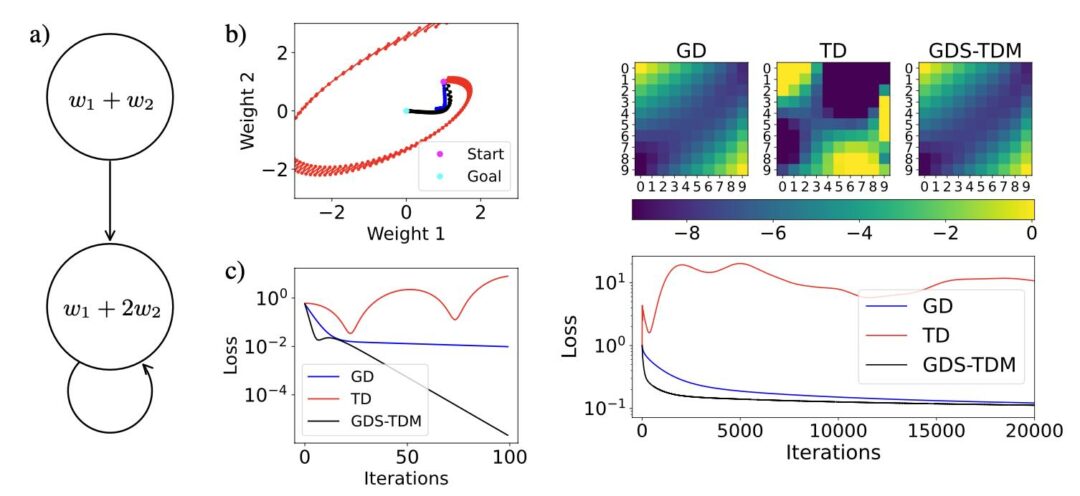
In this paper we solve the decades-old puzzle of why temporal difference learning (TD) can solve complex reinforcement learning (RL) tasks that Gradient Descent cannot. Our novel theoretical view shows how TD (in 2D) effectively counters ill-conditioning, the very property that makes gradient methods impractically slow. This has the potential to become a cornerstone theorem in modern optimization, suggesting that the future for unsupervised, physics-informed deep learning lies in “non-gradient” methods.
Full paper: https://openreview.net/forum?id=j3bKnEidtT
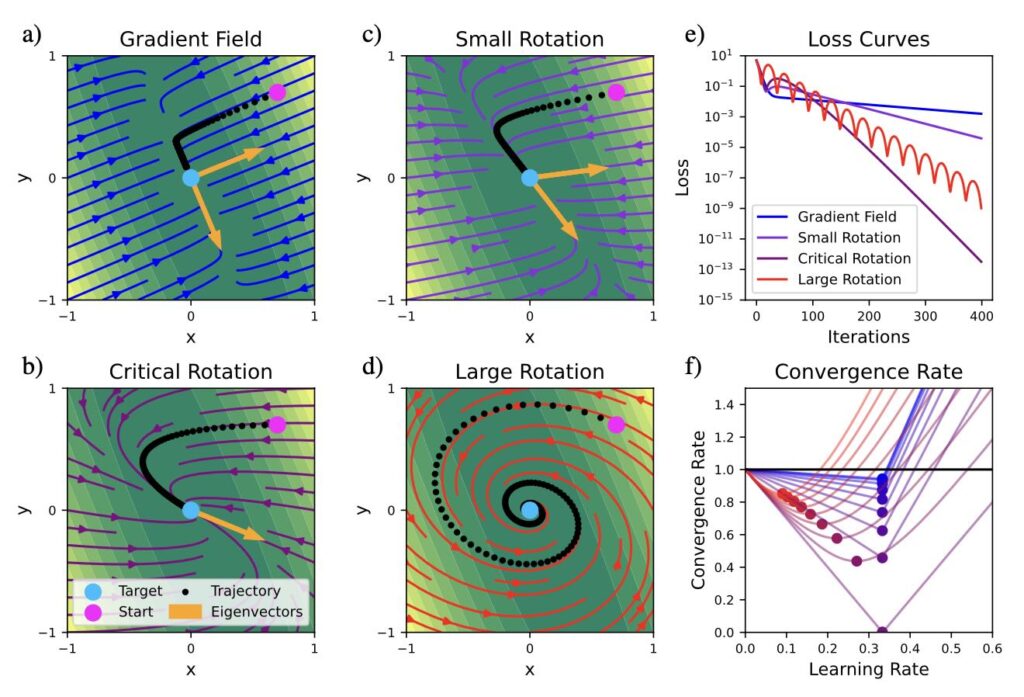
Full abstract: Temporal difference (TD) learning represents a fascinating paradox: It is the prime example of a divergent algorithm that has not vanished after its instability was proven. On the contrary, TD continues to thrive in reinforcement learning (RL), suggesting that it provides significant compensatory benefits. Empirical evidence supports this, as many RL tasks require substantial computational resources, and TD delivers a crucial speed advantage that makes these tasks solvable. However, it is limited to cases where the divergence issues are absent or negligible for unknown reasons. So far, the theoretical foundations behind the speed-up are also unclear. In our work, we address these shortcomings of TD by employing techniques for analyzing iterative schemes developed over the past century. Our analysis reveals that TD possesses a mechanism enabling efficient mapping into the smallest eigenspace—an operation previously thought to necessitate costly matrix inversion. Notably, this effect is independent of the conditioning of the problem, making it particularly well-suited for RL tasks characterized by rapidly increasing condition numbers through delayed rewards. Our novel theoretical understanding allows us to develop a scalable algorithm that integrates TD’s speed with the reliable convergence of gradient descent (GD). We additionally validate these improvements through a rigorous mathematical proof in two dimensions, as well as experiments on problems where TD and GD falter, providing valuable insights into the future of optimization techniques in artificial intelligence.